Trainieren Ihrer NLP-Modelle
Nachdem Sie Ihre Dokumentdefinition veröffentlicht haben, schließen Sie das Dialogfeld Dokumentdefinition , navigieren zum Bereich Trainingsstapel für Feldextrahierung und erstellen einen neuen Dokumentstapel.
- Klicken Sie auf Datei > Neuer Stapel.
- Wählen Sie im daraufhin angezeigten Dialogfeld die zuvor von Ihnen erstellte Dokumentdefinition und wählen Sie den Bereich aus, für den Sie Felder konfiguriert haben und klicken Sie auf OK.
- Wählen Sie im Fenster Look up Variant for Training Batch die Variante aus, die für das Training verwendet werden soll.
- Wählen Sie den neu erstellten Stapel aus und wählen Sie entweder die Option NLP batchoder klicken Sie auf Training für Feldextrahierung > NLP batch.
NLP-Stapeloption
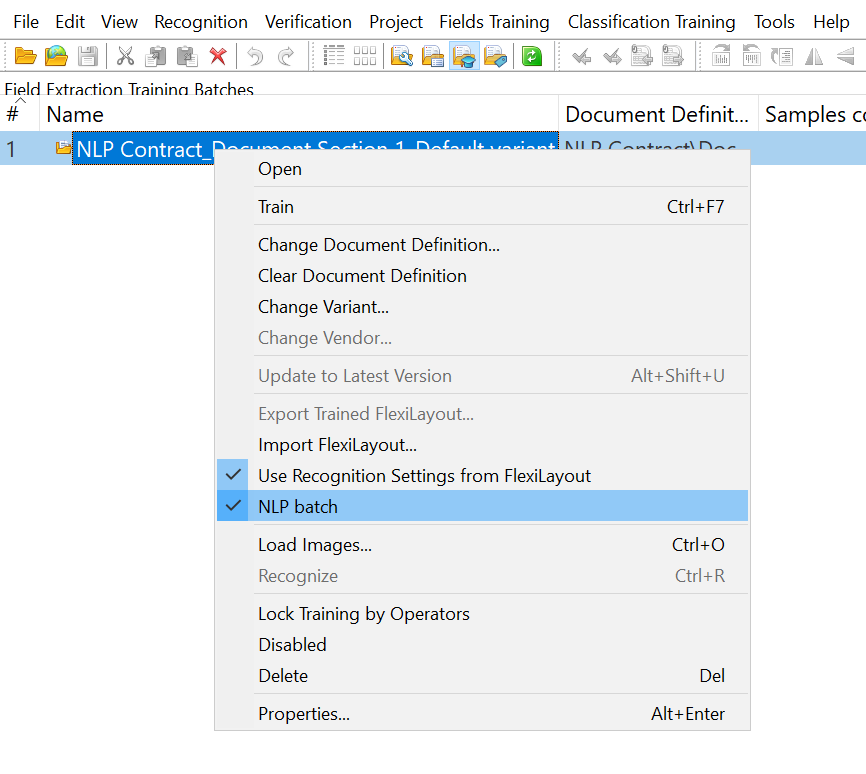
Jetzt müssen die Dokumente geladen werden, die für das Trainieren des NLP-Modells verwendet werden.
- Öffnen Sie den von Ihnen erstellten Stapel per Doppelklick .
- Klicken Sie auf Datei > Bilder laden....
- Klicken Sie im daraufhin angezeigten Dialogfeld auf Einstellungen für die Bildverarbeitung..., wählen Sie die Option EinDokument pro Datei und klicken Sie auf OK.
- Wählen Sie die Dokumente für das Trainieren des NLP-Modells aus.
- Nachdem alle Dokumente geladen wurden, wählen Sie diese aus und klicken auf Erkennung > Dokumentdefinition zuordnen. Alternativ mit der rechten Maustaste die Auswahl anklicken und auf Dokumentdefinition zuordnen klicken. Wählen Sie dann die entsprechende Dokumentdefinition aus.
Die Qualität eines trainierten NLP-Modells hängt von der Anzahl der Dokumente im Trainingsstapel und der Qualität ihrer Markierungen ab. Bitte beachten Sie Folgendes:
- Alle Felder, die durch die Dokumentdefinition beschrieben werden, müssen in den Trainingsdokumenten markiert sein.
- Es wird empfohlen, zwischen 100 und 500 Dokumente in jedem Trainingsstapel zu haben. Diese Anzahl von Dokumenten ermöglicht es dem Programm, die besten Parameter für Ihr NLP-Modell auszuwählen, ohne den Trainingsprozess zu verlangsamen.
Nachdem Sie die Dokumente erfolgreich geladen haben, müssen die Felder der Dokumente per Hand markiert werden, damit die NLP-Modelle wissen, wo nach Einheiten gesucht werden soll. Führen Sie dafür für jedes Dokument die folgenden Schritte aus:
- Doppelklicken Sie auf ein Dokument, um es zu öffnen.
- Wählen Sie ein Feld aus, für das Informationen aus dem Dokument extrahiert werden sollen. Wählen Sie dann entweder den Wert des Feldes auf dem Dokument oder zeichnen Sie ein Rechteck darum. Wiederholen Sie den Schritt für jedes Feld.
- Gehen Sie zum nächsten Dokument, indem Sie auf die Schaltfläche
 klicken. Wiederholen Sie die oben genannten Schritte für alle verbleibenden Dokumente.
klicken. Wiederholen Sie die oben genannten Schritte für alle verbleibenden Dokumente. - Speichern Sie die Änderungen.
Kehren Sie zur Ansicht Trainingsstapel für Feldextrahierungzurück, nachdem Sie alle Dokumente markiert haben. Klicken Sie mit der rechten Maustaste auf den Stapel und klicken Sie im Kontextmenü auf Lernen. Nach dem Training ist das Modell einsatzbereit.
Die Trainingsergebnisse können entweder deaktiviert oder gelöscht werden. Um die Trainingsergebnisse zu deaktivieren, klicken Sie mit der rechten Maustaste auf den Trainingsstapel und wählen das Element Deaktiviert im Kontextmenü aus. Um die Trainingsergebnisse zu löschen, klicken Sie mit der rechten Maustaste auf den Trainingsstapel und wählen das Element Löschen im Kontextmenü aus.
Ein trainiertes NLP-Modell kann in einem anderen Projekt verwendet werden. Importieren Sie dafür den Trainingsstapel und die entsprechende Dokumentdefinition in ein Projekt Ihrer Wahl.
12.04.2024 18:16:01