要素の検索でのNearestおよびFuzzyQualityの使用
 重要!わかりやすいように、このサンプルでは1ページの文書が使用されています。
重要!わかりやすいように、このサンプルでは1ページの文書が使用されています。
文書処理では、「上下左右」のような要素に関連する要素の位置を記述するには不十分な状況が起こったりします。例えば、検索制限に合致する複数のオブジェクトが検索領域に存在する場合です。このような状況では、追加的な差別化特性、具体的にはオブジェクト間の距離が必要です。これを目的として、FlexiLayout StudioにはFuzzyQuality関数、グループNearest関数(Nearest、NearestX、NearestY)があります。
これらの関数の応用は異なります。
関数Nearestは高度な検索前関係フィールドでしか使えません。これは、要素の複数の仮説の中で、Nearest関数のプロパティにおける画像セットの特定の要素または点に最も近い要素を探すよう指定するものです。要素の高度な検索前関係フィールドでは、Nearestグループの1つの関数しか使用できません。実行後、1つの仮説のみが残ります。これは仮説生成の段階すなわち高度な検索後関係フィールドで指定されたコードが実行される前に起こります。要素の仮説の最小品質を指定する最小品質パラメータは、静的テキスト、CharacterString、段落、日付、区切り要素で指定できます。残っている仮説が最善だ(また画像の必須オブジェクトに対応する)という保証はありません。高度な検索後関係は、仮説に品質値を割り当てるためにとても重要であるためです。関数Nearestを使用する時、仮説の選択は仮説生成の段階で行われ、仮説の質ではなく、点への近接に基づいています。高度な検索後関係セクションで指定された特性が仮説の正しい選択に重要である場合に、 Nearestグループの関数の代わりにFuzzyQuality関数を使用する、ということを常に考慮に入れておきます。
FuzzyQuality関数は高度な検索後関係セクションでしか使えません。Nearestグループの関数とは異なり、これは単一の仮説を選択せず、これらの仮説の特性と関数FuzzyQualityのパラメータに基づき、生成されたすべての仮説の質全体に影響を及ぼします。また、FuzzyQuality関数は、高度な検索後関係フィールドの単一要素で複数回使用できます。これは、異なる品質値の複数の異なる制限を仮説に適用できることを意味します。すべての値が乗算されて、仮説の検索後品質が割り出されます。FuzzyQuality関数は以下のようになります:
FuzzyQuality: x, {f1, f2, f3, f4};
このアルゴリズムは以下の通りです: 関数は、パラメータxの値がパラメータf1、f2、f3、f4によって定義された間隔に属するかを確認します。このあいまい間隔の意味は、文字列要素の複数のパラメータで指定されたあいまい間隔に類似しています。
NearestおよびFuzzyQuality関数がいかにして以下の画像で使用されるかを見ていきましょう。
 |
 |
 |
 |
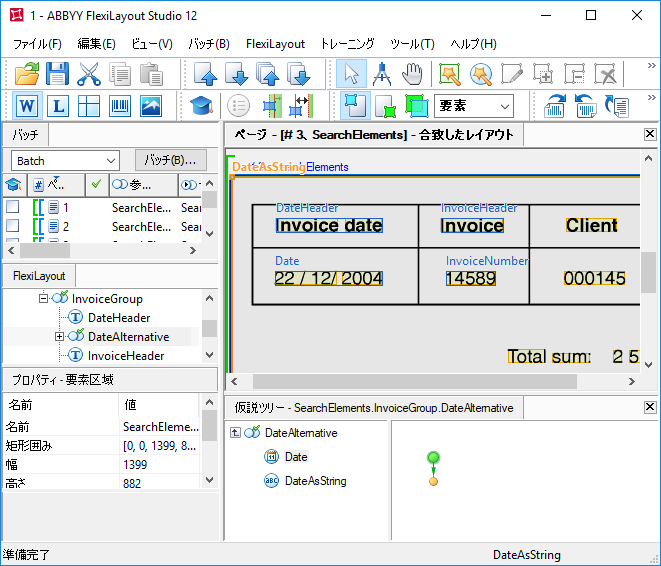
画像の通り、請求書の文書は半構造化であり、フィールドの配置は画像によって異なります。フィールド「請求書番号」と「請求日」を検出します。
このために、1.fspプロジェクトを作成しました(フォルダ%public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\FuzzyAndNearest \Project1)。
FlexiLayout構造を最適化し、文書で求められるフィールドの配置の背後にある論理に従うために、求められるすべての要素を複合要素InvoiceGroupにグループ化しました。フィールド「請求書番号」の名前に対して検索制限を記述する要素を作成し、FlexiLayoutの作成を開始することができます。ですが、画像の分析により、名前を構成する単語「請求書」が文書に数回でてくることが示されています。フィールドの相対位置は毎回変わるため、単語「請求書」の正確な検出を保証する制限を指定することができません。これは、例えば、名前「請求日」にあるかもしれません。このような混乱を避けるために、名前DateHeaderの静的テキスト種類の要素を使用して、日付フィールドの名前の記述を開始しました。検索テキストフィールドに、名前の2つの値を指定しました:Invoicedate:|Invoicedate (名前のバリエーションが画像に発生した時にそれらをリスト化)。名前の大文字小文字は関係ありません。
 注意:複数の静的テキスト値の設定をご覧ください。なぜ両方のバリエーションを指定する必要があるのかの詳細については、類似の値のある静的テキストを検索してください。
注意:複数の静的テキスト値の設定をご覧ください。なぜ両方のバリエーションを指定する必要があるのかの詳細については、類似の値のある静的テキストを検索してください。
フィールド名を頼って日付フィールドを探します。プロジェクトでは、2つの要素からなるグループDateAlternativeを作成しました: 指定形式の1つで日付フィールドを検索する日付要素、および求められるフィールドの形式が異なる場合の種類文字列の要素。
注意:日付検索のためのFlexiLayout作成の詳細は、質の低い事前認識での日付の検出をご覧ください。
画像の通り、日付フィールドは名前「請求日」の右または下に置くことができます。関係フィールドで標準の検索制限を設定すると(これらはプロジェクトで表示されますが無効です)、検索領域が大きくなりすぎて、日付フィールドと間違えられるフィールドを囲むことがあります(画像で例示)。これは、例えば、日付が要素日付で指定された形式と合致しない場合に発生する可能性があります。
不要な領域の分析を防ぐために、別の方法を使用しました。高度な検索前関係フィールドで以下のコードを書きます:
let Header = InvoiceGroup.DateHeader;
if not Header.IsNull then
{ let rect1 = Rect (Header.Rect.Right, Header.Rect.Top-20dt,
PageRect.Right, Header.Rect.Bottom+20dt);
let rect2 = Rect (Header.Rect.Left - 200dt, Header.Rect.Bottom,
Header.Rect.Right + 150dt, Header.Rect.Bottom+200dt);
RectArray ar;
ar = RectArray ( rect1 );
ar.Add ( rect2 );
RestrictSearchArea( ar );
}
else
{ Above: PageRect.Top + PageRect.Height/2;
}
コードは、日付フィールドの名前が見つかったかどうかを確認するものです。見つかった場合は、検索領域を矩形配列として指定します(例 - 2つの矩形)。1つの矩形は名前の右の日付を検索し、もう1つの矩形は下を検索します。名前が見つからない場合、検索は画像の上半分で実行されます。
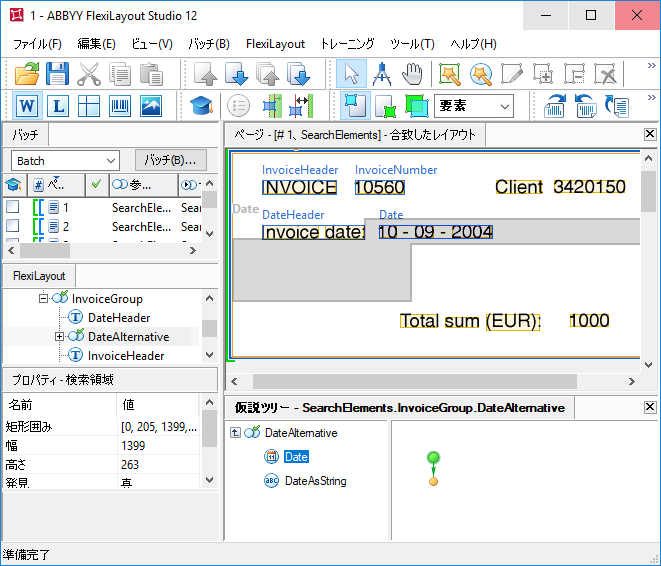
関係セクションで検索制限が指定されたページの場合、このコードを実行した後の検索領域の形は矩形とは異なります。画像の通り、不要なオブジェクトはすべて削除されました。
注意:コードの最初の行(let Header = InvoiceGroup.DateHeader;)は、変数Headerを定義し、要素DateHeaderの値を割り当てることで、コードを簡略化します。
要素DateAsStringで上記コードを複製しませんでしたが、高度な検索前関係セクションで以下の検索制限を書きました:
if not Date.IsNull then Dontfind();
else RestrictSearchArea (Date.Rect);
この意味は、要素日付が検出されない場合、要素日付の検索領域を囲む矩形で検索を実行する、です。
注意:要素DateAsStringの検索領域を、RestrictSearchArea (Date.Rect)を呼び出す代わりに、矩形配列として指定するには、対応するコードを要素日付の高度な検索前関係セクションから重複させます。
次に、フィールド「請求書番号」の名前を検出するために種類静的テキストの要素(名前InvoiceHeader)を作成して、求められる値を指定しました:"Invoice".文書は構造化されていないため、特定の検索制限を与えることはできません。
FlexiLayoutの合致が完了すると、名前が最初のページでのみ正確に検出されていることがわかります。ページ2と4では、単語「請求書」が日付フィールドの名前で間違って検出されました。ページ3では、ページの下部で発見され、また最適化アルゴリズムに従って、単語「請求書」が画像で3回発生していても、名前の他の仮説は生成されませんでした。
注意:グループでの要素の最適な検索に関する詳細は、グループ要素検索の最適化をご覧ください。
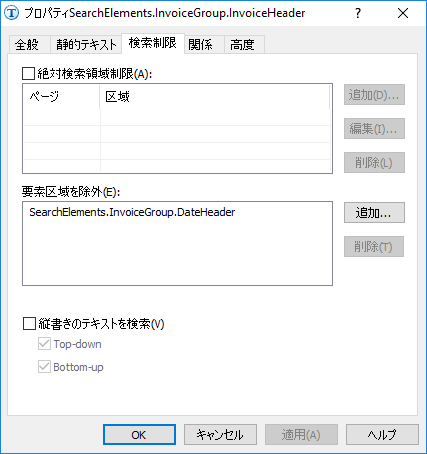
これらの問題を解決するために、以下の方法を使いました。日付フィールド名の区域をフィールド名「請求書」の検索領域から除外するために、要素DateHeaderをセクション要素区域を除外に追加しました(下の画像)。
注意:FlexiLayoutの作成を、名前DateHeaderではなく、名前InvoiceHeaderで始めていたら、除外関数を使えなかったでしょう。この関数はプロジェクトツリーの現在の要素よりも高い位置にある要素しか除外できないためです。
ページ下部で単語「請求書」の不要な検出をしないよう、高度な検索前関係セクションで以下のコードを書きました。
NearestY: PageRect.Top;
このコードで、ページの上端に最も近い要素を検索するよう指示します。
FlexiLayoutが合致すると、ここの日付フィールドの名前はノイズの多さで検出されなかったために、ページ2で方法が失敗したことがわかります。このページでは、Nearest関数で指定された制限は、「請求書」文字列の両方で真でした。文字列が同じ水準に位置しているためです。また、「請求書」文字列の認識の質はどちらでも良好であるため、最適化アルゴリズムは、2つの個別の仮説ではなく、1つの仮説を生成しました。残念ながら、この仮説は正しくありません。
「請求書番号」フィールドを検出するために、種類文字列の名前InvoiceNumber付き要素を作成しました。日付フィールドの要素と同様、高度な検索前関係セクションで「請求書」フィールドの検索制限を指定しました。この要素の検索領域は矩形配列です。
let Header = InvoiceGroup.InvoiceHeader;
if not Header.IsNull then
{ let rect1 = Rect (Header.Rect.Right, Header.Rect.Top-20dt,
PageRect.Right, Header.Rect.Bottom+20dt);
let rect2 = Rect (Header.Rect.Left - 200dt, Header.Rect.Bottom,
Header.Rect.Right + 150dt, Header.Rect.Bottom+200dt);
RectArray ar;
ar = RectArray( rect1 );
ar.Add( rect2 );
RestrictSearchArea( ar );
}
else
{ Above: PageRect.Top + PageRect.Height/2;
}
Nearest: Header;
また、コードにもう1つの制限を追加しました。要素InvoiceNumberは名前の要素に最も近い、と指示しました。
合致の実行後、ページ2と4で「請求書番号」フィールドが間違って検出されていたことがわかります。フィールドの名前が正しく検出されたにもかかわらず、ページ4で間違って検出されました。
注意:Nearestの代替(現在のプロジェクトの画像)として:Header;、NearestYを書くことができます:Header.Rect.YCenter;、求められたフィールドが名前の中心に垂直に最も近いことを指示します。これで、ページ4のフィールド「請求書番号」の間違った検出を解決することができます。ただし、求められるフィールドが名前「請求書番号」が間違って検出された後で日付フィールド内で検出されるため、ページ5では役に立ちません。
このような状況でどうやってFuzzyQuality関数を使うかを見ていきましょう。
このために、プロジェクト2.fspを作成しました(FuzzyAndNearest\Project2フォルダ)。
このプロジェクトの設定は、上記のプロジェクトの設定とほぼ同じです。
ですが、大きな違いが1つあります。Nearest関数を、高度な検索前関係セクションで使いませんでした。代わりに、以下のコードを高度な検索後関係セクションで書きました:
if not IsNull then
{ FuzzyQuality: Rect.Top - PageRect.Top, {0,0,0,50000} * dt;
FuzzyQuality: 500dt-Width, {0,0,0,100000} * dt;
if not InvoiceHeader.IsNull then
{ FuzzyQuality: Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt;
FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt;
}
}
この方法では、すべての仮説の質に影響を及ぼすことができます。最善の連鎖の選択は、要素のすべての構成仮説の品質値が乗算されながら、各連鎖で個別に行われます。
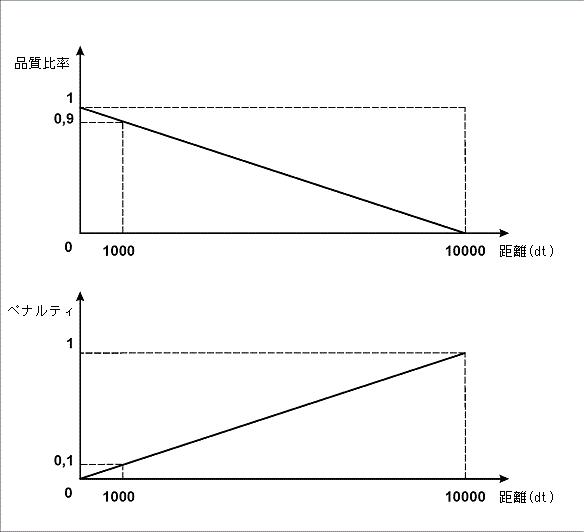
行FuzzyQuality:Rect.Top - PageRect.Top, {0,0,0,50000} * dt;の意味は、非帰無仮説が生成された(if not IsNull確認が最初に実行された)場合、要素の位置とページの上端の間の距離が割り出される、というものです。すなわち差(Rect.Top - PageRect.Top)が計算され、この差が間隔{0, 0, 0, 50000}*dtに属するかが確認されます。このような間隔の記述は、品質ペナルティおよび要素とページの上端の間の距離に直接依存関係を意味し、距離が長いほど、ペナルティは大きくなります。画像の通り、指定パラメータ値で、最大ペナルティ(1)は距離50000dtに対応し、 距離1000dt(1ドットは1/300インチ)はペナルティ0.02、距離100dtはペナルティ0.002です。
注意:間隔の境界を設定するパラメータを選択する時、このようなパラメータを選択して (特にFuzzyQuality関数での要素確認が複数ある時)正しい仮説がその最終品質で帰無仮説より低くなる程度までペナルティが科されないようにします。すべての仮説の質(正しいものを含む)が帰無仮説の品質値よりも低い場合、帰無仮説が選択され、すなわち要素が検出されません。
(a)
行FuzzyQuality:500dt - Width, {0,0,0,100000}*dt;の意味は、500dtの仮説に対応する検出されたオブジェクトの幅の差を考慮する、というものです。すなわち差(500dt - 幅)が計算され、この差が間隔{0, 0, 0, 100000}*dtに属するかが確認されます。オブジェクトが狭いほどペナルティは大きくなるため、長い請求書番号が好ましいです。この制限は、画像にノイズが多い場合に使用できます。ノイズが指定のアルファベットの文字として認識された場合(例えば、ページ2のように)、その仮説はさらなる分析から除外されるようペナルティを科せられるべきです。
注意:500dtの値が、フィールド「請求書番号」の文字列の長さはこの値より大きくないと仮定して、目視検査で選択されます。ここで指定されたパラメータは、最大ペナルティ(0.005)がフィールド「請求書番号」のゼロ幅に対応することを定義します。0~500dtの他の幅については、品質ペナルティは低くなります。
行FuzzyQuality:Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt;の意味は、「請求書番号」フィールドの名前の要素の非帰無仮説が生成された(if not InvoiceHeader.IsNull確認が最初に実行された)場合、検出された要素InvoiceNumberの中心と名前InvoiceHeaderの中心の間の距離が割り出される、というものです。差(Rect.XCenter - InvoiceHeader.Rect.XCenter)が計算され、この差が間隔{-10000, 0, 0, 50000}*dtに属するかが確認されます。この記述は、フィールド「請求書番号」が名前の下にある可能性も考慮しています。この場合、要素が互いに離れているほど、対応する仮説のペナルティが大きくなります。番号が名前の右にあるという仮説は、番号が名前の下にあるという仮説ほどペナルティを科されません。フィールド「請求書番号」の「正しい」配置、はるかに一般的な名前は、明白だからです。
画像(b)の通り、間隔の左右境界の指定パラメータで、最大ペナルティ(1)はフィールド「請求書番号」の名前フィールドから左に10000dtの移動、または右に50000dtの移動に対応します。1000dtの移動は「左」移動である場合にペナルティ0.1、「右」移動である場合にペナルティ0.02になります。同様に、100dtの移動は「左」移動である場合にペナルティ0.01、「右」移動である場合にペナルティ0.002になります。
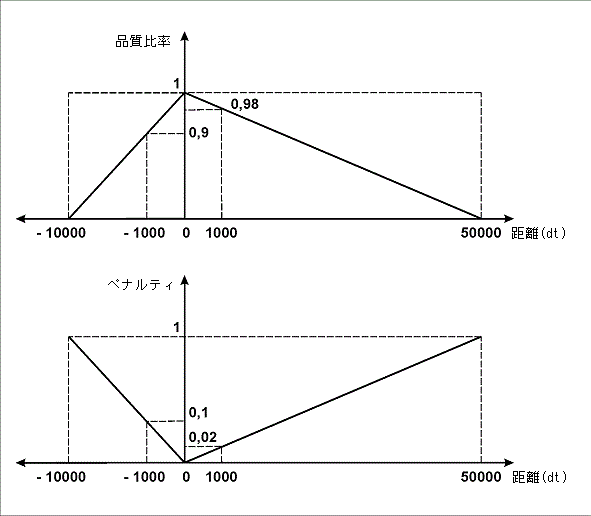
(b)
行FuzzyQuality:Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt;は前のものと同じです。ですが、フィールド「請求書番号」が名前のフィールドと同じ横水準にある場合、または若干高い場合に、これは留保されます。ここでのペナルティは、縦移動の場合と同じです。間隔の境界は、その名前の右にデータフィールドを探す仮説の優先順位をサポートするという同じ論理に従って、設定されます。ただし、この設定では、名前の下にあっても請求書番号の正確な検出が妨げられることはありませんでした(ページ3)。
FlexiLayoutをすべてのページと合致させた後、2つの求められるフィールドが正常に検出されていることがわかります。
結論として、FuzzyQuality関数はNearestグループの関数よりも効率的、柔軟であると言えます。これは半構造化文書の処理の時に特に重要です。
4/12/2024 6:16:07 PM