Using Nearest and FuzzyQuality to search for elements
 Important!For the sake of simplicity, a one-page document is used in this sample.
Important!For the sake of simplicity, a one-page document is used in this sample.
In documents processing there are often situations when it is not enough to describe the location of elements relative to other elements in terms of the "above - below - to the right - to the left" kind. This may happen, for example, if in the search area there are several objects matching the search constraints. In such situations we need additional differentiating properties, specifically - the distance between the objects. For these purposes FlexiLayout Studio has the FuzzyQuality function, as well as the functions of the group Nearest (Nearest, NearestX, NearestY).
The applications of these functions are different.
The function Nearest can only be used in the Advanced pre-search relations field. It specifies that, among the several hypotheses of the element, the program must look for the nearest one to a certain element or point on the image set in the properties of the Nearest function. In the Advanced pre-search relations field of the element, only one function of the Nearest group can be used. After it is run, only one hypothesis is left, and it happens at the stage of hypotheses generation, i.e. before the code specified in the Advanced post-search relations field is run. The Minimum quality parameter, which specifies the minimum quality of hypotheses for the element, can be specified for the StaticText, CharacterString, Paragraph, Date and Separator elements. There is no guarantee that the remaining hypothesis is the best (and corresponds to the required object of the image), because Advanced post-search relations are very important for assigning a quality value to a hypothesis. When using the function Nearest, the choice of hypothesis is made at the stage of hypotheses generation and is based on the proximity to some point, not on the quality of the hypothesis. It should always be taken into consideration that if the properties specified in the Advanced post-search relations section are important for the correct selection of the hypothesis you should use the FuzzyQuality function instead of the functions of the Nearest group.
The FuzzyQuality function can only be used in the Advanced post-search relations section. Unlike the functions of the Nearest group, it doesn't select a single hypothesis but instead influences the overall quality of all the generated hypotheses based on the properties of these hypotheses and the parameters of the function FuzzyQuality. Besides, the FuzzyQuality function can be used multiple times for a single element in the Advanced post-search relations field. This means that several different constraints with different quality values can be applied to a hypothesis. All the values will be multiplied to determine the Post-search quality of the hypothesis. The FuzzyQuality function looks as follows:
FuzzyQuality: x, {f1, f2, f3, f4};
Its algorithm is as follows: the function checks whether the value of the parameter x belongs to the interval defined by the parameters f1, f2, f3, f4. The meaning of this fuzzy interval is similar to the fuzzy intervals specified for some of the parameters of the Character String element.
Let us see how the Nearest and FuzzyQuality functions can be used on the following images.
 |
 |
 |
 |
As is seen from the pictures, the document of the invoice is semi-structured, as the arrangement of the fields is different on different images. We are going to detect the fields "Invoice number" and "Invoice date".
To do this, we created the 1.fsp project (folder %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\FuzzyAndNearest \Project1).
To optimize the FlexiLayout structure and to follow the logic behind the arrangement of the sought fields in the document, we grouped all the sought elements into a compound element, InvoiceGroup. We can start FlexiLayout creation with the creation of an element describing the search constraints for the name of the field "Invoice number". But the analysis of the images shows that the word "Invoice", which makes up the name, is encountered on the document several times. Since the relative location of the fields changes each time, we cannot specify the constraints that would guarantee the correct detection of the word "Invoice". It may, for example, be found in the name "Invoice date". To avoid such confusion, we started the description of the name of the date field by using an element of the Static Text type, named DateHeader. In the Search text field we specified two values of the name: Invoicedate:|Invoicedate (listing the variants of the name as they occur on the images). The letter case of the name is irrelevant.
 Note.See Setting multiple static text values. Search for static text with similar values for details on why you must specify both the variants.
Note.See Setting multiple static text values. Search for static text with similar values for details on why you must specify both the variants.
We are going to look for the date field relying on the field name. In the project we have created a group DateAlternative, which consists of two elements: a Date element to search for the date field in one of the specified formats, and an element of type Character String, in case the format of the sought field is different.
Note.See Detecting dates in the case of low quality pre-recognition for a detailed description of creating a FlexiLayout for date search.
As is seen from the images, the date field can either be located to the right of the name "Invoice date" or below it. If we set standard search constraints in the Relations field (these are displayed in the project, but disabled), then the search area will be too large, and may enclose some fields that may be mistakenly taken for the date field (an example is shown in the picture). This may happen, for instance, if the date doesn't match the format specified for the element Date.
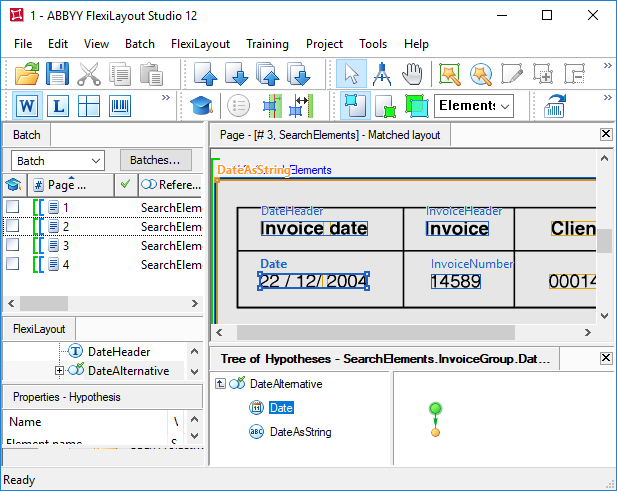
To prevent the program from analyzing the unwanted area, we used an alternative method. In the Advanced pre-search relations field we wrote the following code:
let Header = InvoiceGroup.DateHeader;
if not Header.IsNull then
{ let rect1 = Rect (Header.Rect.Right, Header.Rect.Top-20dt,
PageRect.Right, Header.Rect.Bottom+20dt);
let rect2 = Rect (Header.Rect.Left - 200dt, Header.Rect.Bottom,
Header.Rect.Right + 150dt, Header.Rect.Bottom+200dt);
RectArray ar;
ar = RectArray ( rect1 );
ar.Add ( rect2 );
RestrictSearchArea( ar );
}
else
{ Above: PageRect.Top + PageRect.Height/2;
}
The code checks whether the name of the date field has been found. If it has been found, we specify the search area as an array of rectangles (in the example - 2 rectangles). One rectangle searches for the date to the right of the name, the other - below the name. If the name is not found, the search will be run in the upper half of the image.
In the case of a page where the search constraints were specified in the Relations section, the form of the search area after running this code will be different from a rectangle. As is seen in the picture, all the unwanted objects were removed from it.
Note.The first line of the code (let Header = InvoiceGroup.DateHeader;) simplifies the code by defining the variable Header and assigning it the value of the element DateHeader.
We didn't duplicate the above code for the element DateAsString, but wrote the following search constraint in the Advanced pre-search relations section:
if not Date.IsNull then Dontfind();
else RestrictSearchArea (Date.Rect);
It means that if the element Date is not detected, the search will be run in the rectangle enclosing the search area of the element Date.
Note.To specify the search area of the element DateAsString as an array of rectangles, instead of calling RestrictSearchArea (Date.Rect), duplicate the corresponding code from the Advanced pre-search relations section of the element Date.
Then we created an element of type Static Text (named InvoiceHeader) to detect the name of the field "Invoice number", and specified the sought value: "Invoice". Since the document is not structured, we are unable to give any specific search constraints.
Once the FlexiLayout matching procedure is finished, we can see that the name has been accurately detected only on the first page. On pages 2 and 4, the word "Invoice" was mistakenly detected in the name of the date field. On page 3, it was found at the bottom of the page, and, according to the optimization algorithm, the other hypotheses of the name were not generated, even though the word "Invoice" occurs on the image three times.
Note.See the Optimizing Group element search for more information on optimal search for elements in the group.
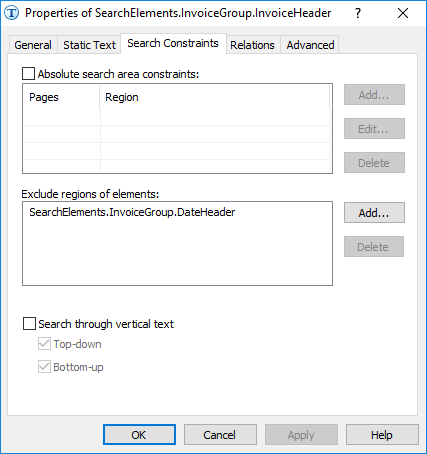
To solve the problems, we used the following method. To exclude the region of the name of the date field from the search area of the field name "Invoice", we added the element DateHeader to the section Exclude regions of elements (see the picture below).
Note.If we had started creating the FlexiLayout not with the name DateHeader but with the name InvoiceHeader, we wouldn't have been able to use the Exclude function, as this function can only exclude elements that are located higher than the current element in the project tree.
To exclude the unwanted detection of the word "Invoice" at the bottom of the page, we wrote the following code in the Advanced pre-search relations section.
NearestY: PageRect.Top;
This code tells the program to search for the element nearest to the top edge of the page.
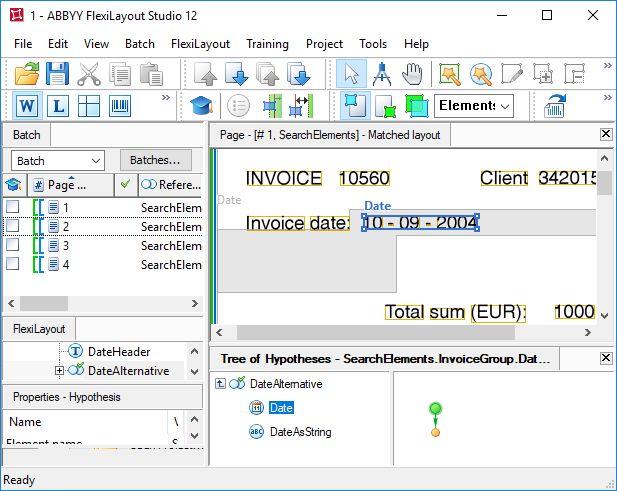
Once the FlexiLayout has been matched, we see that our method failed on page 2, because the name of the date field here is very noisy and wasn't detected. On this page, the constraint specified in the Nearest function is true for both of the "Invoice" strings, because they are located on the same level. And since the recognition quality of the "Invoice" strings is good in both the cases, the optimization algorithm generated a single hypothesis instead of two separate ones. Unfortunately, this hypothesis is not correct.
To detect the "Invoice number" field, we created an element of type Character String, named InvoiceNumber. Similarly to the element for the date field, we specify the search constraints for the "Invoice number" field in the Advanced pre-search relations section. The search area for this element is an array of rectangles.
let Header = InvoiceGroup.InvoiceHeader;
if not Header.IsNull then
{ let rect1 = Rect (Header.Rect.Right, Header.Rect.Top-20dt,
PageRect.Right, Header.Rect.Bottom+20dt);
let rect2 = Rect (Header.Rect.Left - 200dt, Header.Rect.Bottom,
Header.Rect.Right + 150dt, Header.Rect.Bottom+200dt);
RectArray ar;
ar = RectArray( rect1 );
ar.Add( rect2 );
RestrictSearchArea( ar );
}
else
{ Above: PageRect.Top + PageRect.Height/2;
}
Nearest: Header;
Additionally, we added one more constraint to the code. We told the program that the element InvoiceNumber is the nearest to the element of the name.
After running the matching procedure, we see that the "Invoice number" field was detected wrongly on pages 2 and 4. It was wrongly detected on page 4 even though the name of the field was detected correctly.
Note.As an alternative (for the images of the current project) to Nearest: Header;, we could write NearestY: Header.Rect.YCenter;, to tell the program that the sought field is vertically nearest to the center of the name. This could solve the problem of the incorrect detection of the field "Invoice number" on page 4. But it doesn't help on page 5, because the sought field is detected within the date field after the incorrect detection of the name "Invoice number".
Now let's see how we can use the FuzzyQuality function in such a situation.
To demonstrate this, we created the project 2.fsp (FuzzyAndNearest\Project2 folder).
The settings of this project are nearly identical to those of the project described above.
But there is one significant difference. We didn't use the Nearest function in the Advanced pre-search relations section. Instead, we wrote the following code in the Advanced post-search relations section:
if not IsNull then
{ FuzzyQuality: Rect.Top - PageRect.Top, {0,0,0,50000} * dt;
FuzzyQuality: 500dt-Width, {0,0,0,100000} * dt;
if not InvoiceHeader.IsNull then
{ FuzzyQuality: Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt;
FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt;
}
}
With this method we can affect the quality of all the hypotheses, not excluding any of them. The choice of the best chain will be made for each chain individually by multiplying the quality values of all constituent hypotheses of the elements.
The line FuzzyQuality: Rect.Top - PageRect.Top, {0,0,0,50000} * dt; means, that if a non-null hypothesis is generated (if not IsNull check is run first), then the distance between the location of the element and the top edge of the page is determined. I.e. the difference (Rect.Top - PageRect.Top) is calculated, and the program checks whether this difference belongs to the interval {0, 0, 0, 50000}*dt. Such a description of the interval means that there is a direct dependency of the quality penalty and the distance between the element and the top edge of the page - the longer the distance, the greater the penalty. As is shown in the picture (a), with the specified parameters values, the maximum penalty (1) corresponds to the distance of 50000dt, while the distance of 1000 dots (1 dot is 1/300 of an inch) means the penalty of 0.02, the distance of 100dt - the penalty of 0.002.
Note.When you choose parameters setting the boundaries of the interval, you should choose such parameters (particularly, when there are multiple element checks with the FuzzyQuality function) that won't penalize the right hypothesis to a degree when its final quality will be lower than that of a null hypothesis. If the quality of all the hypotheses (including the correct one) is lower than the quality value of a null hypothesis, the null hypothesis may be selected, i.e. the element won't be detected.
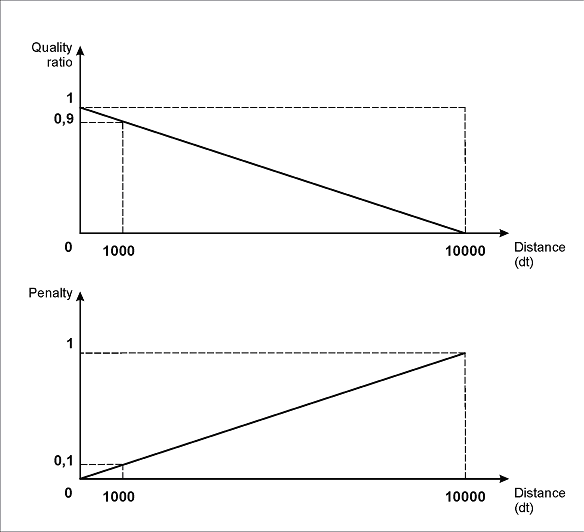
(a)
The line FuzzyQuality: 500dt - Width, {0,0,0,100000}*dt; means that the programs considers the difference of width of the detected object, corresponding to the hypothesis of 500dt. I.e. the difference (500dt - Width) is calculated and the program checks whether this difference belongs to the interval {0, 0, 0, 100000}*dt. The narrower the object, the greater the penalty, so longer invoice numbers will be preferable. This constraint can be used if the image is noisy. If the noise is recognized as a character from the specified alphabet (as it can be seen, for instance, on page 2), its hypothesis should be penalized to exclude it from further analysis.
Note.The value of 500dt is chosen by visual examination, assuming that the string length in the field "Invoice number" is not greater than this value. The parameters specified here define that the maximum penalty (0.005) would correspond to the zero width of the field "Invoice number". For any other widths between 0 and 500dt, quality penalties would be lower.
The line FuzzyQuality: Rect.XCenter - InvoiceHeader.Rect.XCenter, {-10000,0,0,50000} *dt; means that if a non-null hypothesis of the element of the name of the "Invoice number" field is generated (if not InvoiceHeader.IsNull check is run first), then the distance between the center of the detected element InvoiceNumber and the center of the name InvoiceHeader is determined. The difference (Rect.XCenter - InvoiceHeader.Rect.XCenter) is calculated, and the program checks whether this difference belongs to the interval {-10000, 0, 0, 50000}*dt. This description also takes into account the possibility that the field "Invoice number" can be located below the name. In this case, the farther the elements are from each other, the greater is the penalty for the corresponding hypothesis. Hypotheses assuming that the number is located to the right of the name won't be penalized as much as those assuming that the number is below the name, as it is obvious that the "right" arrangement of the field "Invoice number" and its name is much more common.
As is shown in the picture (b), with the specified parameters of the left and the right boundaries of the interval, the maximum penalty (1) will correspond to the shift of the field "Invoice number" from the name field by 10000dt to the left or by 50000dt to the right. A shift of 1000 dot will be penalized by 0.1 if it's a "left" shift, or by 0.02 if it's a "right" shift. Similarly, a shift of 100 dot will be penalized by 0.01 if it's a "left" shift, or by 0.002 - if it's a "right" shift.
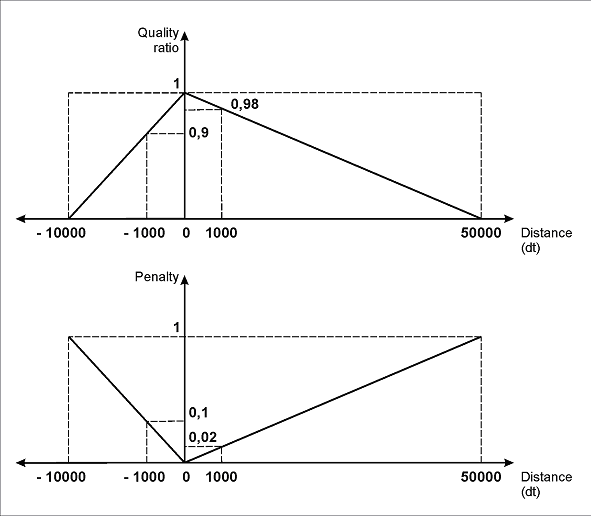
(b)
The line FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} *dt; is identical to the previous one. But it is reserved for the cases when the field "Invoice number" is on the same horizontal level or even slightly higher than the field of the name. Penalties here are the same for any vertical shift. The boundaries of the interval are set, in accordance with to the same logic - to support the priority of hypotheses that find the data field to the right of its name. However, the project shows that these settings didn't prevent the correct detection of the invoice number even when it was located below the name (page 3).
After matching the FlexiLayout with all the pages, we see that the two sought fields have been successfully detected.
In conclusion we can say that the FuzzyQuality function is more efficient and flexible compared to the functions of the Nearest group, which is particularly important when processing of semi-structured documents.
4/12/2024 6:16:02 PM