Optimizing group element search
If all the hypotheses of the chain of elements in the Group element (Group) have the quality value of 1, then the other hypotheses of these elements won't be analyzed.
 Note.This is done to optimize the FlexiLayout, to quicken the matching procedure and to avoid the unwanted "branching" of the tree of hypotheses. But a hypothesis which is optimal for the program does not necessarily correspond to the sought object on the image. This might happen if the search constraints for the element are not strict enough. So, when such a situation arises, you should first of all analyze the parameters set for the elements search.
Note.This is done to optimize the FlexiLayout, to quicken the matching procedure and to avoid the unwanted "branching" of the tree of hypotheses. But a hypothesis which is optimal for the program does not necessarily correspond to the sought object on the image. This might happen if the search constraints for the element are not strict enough. So, when such a situation arises, you should first of all analyze the parameters set for the elements search.
Let's consider the project GO.fsp (folder %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\GO\1), where we are going to search for the field "Invoice number".
The project has 2 pages:
- Page 1 – the image quality is good;
- Page 2 – the name of the sought field is noisy.
We created the group InvoiceGroup, which contains the element used to search for the field name. This is an element of the Static Text type, named InvoiceHeader, with the value "INVOICE". To search for the field "Invoice number" itself we created an element of type Character String, named InvoiceNumber. We specified the search constraints of the date field search relative to the name in the Relations section of the element InvoiceNumber.
Note.The letter-case of the name in the section Search text is irrelevant.
Note that the string "Invoice" specified as the value for the element InvoiceHeader occurs on the images three times: as the name of the "Invoice number" field, as a substring in the name "Invoice date" and at the bottom of the invoice, as a substring in the payment conditions "Current invoice is…". So we can predict that there will be three hypotheses after the matching procedure.
After running the FlexiLayout matching procedure by selecting the Match command, we see that the tree of hypotheses in the group InvoiceGroup has only one complete chain instead of the expected three, and the complete chain of hypotheses left does not correspond to the name we are trying to detect.
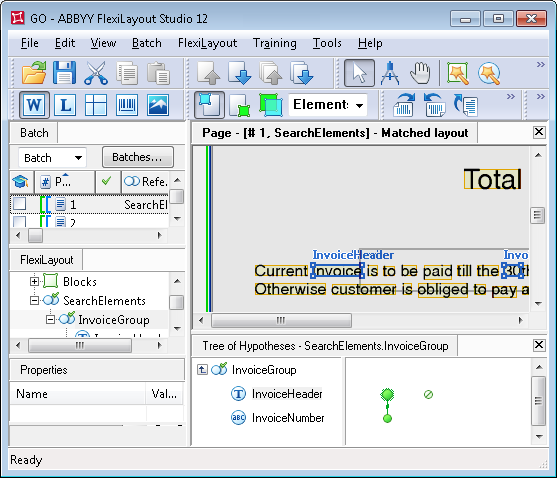
If you look at the properties of each of the elements in the generated chain, you will see that the Chain quality of each hypothesis is 1, which triggered the optimization - when the program detects an ideal chain in terms of quality (i.e. having the quality 1) it ceases to generate hypotheses.
Note.To see the tree of hypotheses of the group, double-click the name of the Group element in the tree of hypotheses, or press Enter, or select the Show Details from the shortcut menu.
Why, at the stage of hypotheses generation, one object of the image is preferable over the others is determined the algorithm of the program.
Since the results of matching the FlexiLayout are unsatisfactory, we should analyze the reasons of the problem and decide how it can be solved.
First, we didn't limit the search area for the element InvoiceHeader. Second, when describing the element InvoiceNumber, we specified that the string of digits can be of any length (because we don't know the possible length of the invoice number). We also specified that it should be looked for to the right of the name, at approximately the same horizontal level. As you can see, all the three instances of the word "Invoice" match these conditions. That's why the incorrect detection of the name automatically caused the incorrect detection of the field "Invoice number". You must add some limiting constraints, so that the correct hypothesis is the best in the end, and the FlexiLayout is optimal not only in terms of matching speed.
If we assume that the arrangement of the fields is identical on all the pages of the project, then the easiest way is to "tell" the program that we need the string "Invoice" which is the nearest element to the right edge of the page. So we write the following code in the Advanced pre-search relations section of the element InvoiceHeader: Nearest: PageRight;. We can do so because the name of the sought field "Invoice number" is the only element nearest to the right edge of the page. If it weren't so or if the document weren't formalized, the Nearest function couldn't help us to solve the problem.
To show alternative ways to do this task, including the case with a semi-structured document, we created the project GO.fsp (folder GO\2).
As you can see on the images, the distance between the digit string and the word "invoice" is the smallest in the sought field "Invoice number". This is true on all the pages, which gives us an opportunity to affect the quality values of generated hypotheses by entering the following code in the Advanced post-search relations section of the element InvoiceNumber:
if (not InvoiceHeader.IsNull) and (not IsNull) then
{ FuzzyQuality: Rect.Left - InvoiceHeader.Rect.Right, {0, 0, 0, 10000}*dt; }
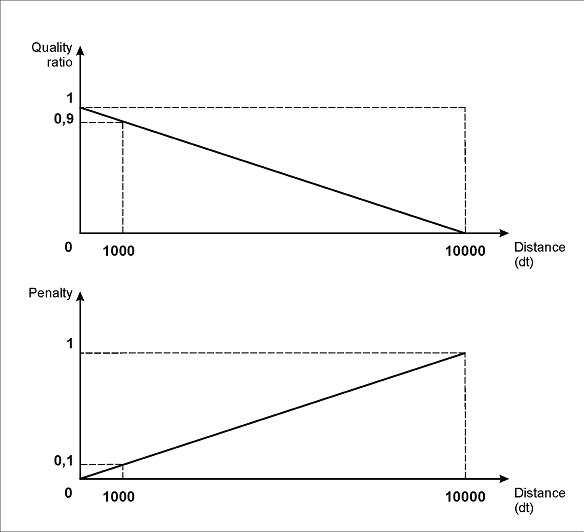
It means that if both elements are detected, the distance between the elements is calculated for the hypothesis of the element InvoiceNumber, and the program checks whether it belongs to the interval {0, 0, 0, 10000}*dt. This description of the interval shows the linear dependency between the quality of the hypothesis and the distance between the elements - the longer the distance, the greater the penalty (the function FuzzyQuality restores the post-search quality of the hypothesis - it can be seen in the Properties window of the hypothesis). The value for the right boundary of the interval (10000dt) was determined experimentally. When choosing this value, you should take into account the distance between the corresponding objects on test images.
As is seen from the picture below, under the specified interval properties, the maximum penalty (1) will correspond to a distance of 10000dt. Accordingly, a distance of 1000dt will bring a penalty of 0.1, a distance of 100dt - a penalty of 0.01, etc.
So for real distances of about 100-300 dot, which we can see on our images, the penalty coefficient will be 0.99-0.97.
Note.See Using Nearest and FuzzyQuality to look for elements for more details about the use of these functions.
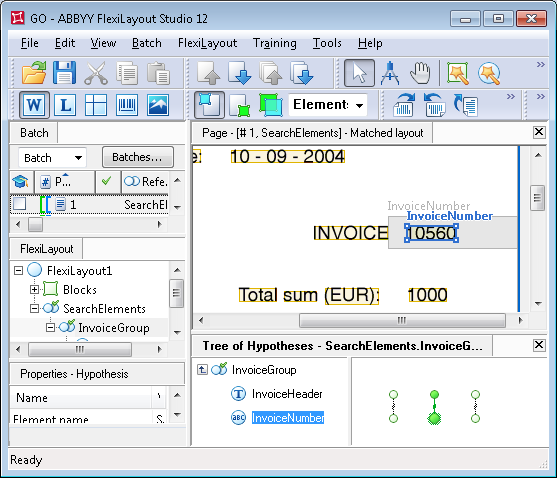
For the images in this batch, the hypothesis corresponding to the unwanted field "Invoice number" with the value "2005" got the maximum penalty, while the hypothesis corresponding to the sought field got the minimum penalty. Since penalizing made the Post-search quality of all the hypotheses different from 1, all the hypotheses of both elements of the Group element InvoiceGroup will now be analyzed.
Note that the field "Invoice number" was correctly detected even on page 2, where the name "Invoice" is very noisy, which caused a recognition error and, consequently, additional penalties for the hypothesis.
4/12/2024 6:16:02 PM