Static Text
Static Text is an element of a FlexiLayout which describes some pre-defined text. The text may consist of a word or of a phrase. Phrases are different from words in that they contain at least one space. A phrase may be written in several lines.
Static Text elements are marked with ![]() in the FlexiLayout tree.
in the FlexiLayout tree.
The program uses Static Text elements to search for static text, i.e. for text which is known in advance. The program will consider Recognized Words and Recognized Lines objects detected during pre-recognition and located in the element’s search area as static text candidates.
Usually all or many images in the batch include static text. This may be the heading of the document (e.g. Invoice) or the names of fields (e.g. Date, to:, From:). Such objects are detected as Recognized Words during pre-recognition are usually used as "signposts" when looking for any text which may be entered in their corresponding fields: for example, it is natural to expect a date next to the static text "Date".
The properties of a Static Text element
Click the Search text from file tab in the Properties dialog box to describe the corresponding object. To open the Properties dialog box, right-click the element in the FlexiLayout tree and select Properties... from the shortcut menu.
Show Properties dialog box, Static Text tab
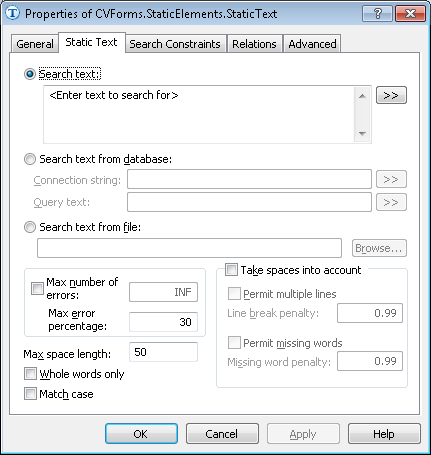
- Search text
the text to find on the image.
If you need to find a phrase or several words and you know that they will always be located on the same line, it is recommended to ignore spaces (i.e. leave unchecked the option Take spaces into account), as this will speed up the search. In this case, you can type in your search phrase without spaces - the program will remove them anyway if the Take spaces into account option is not selected.
| E.g.: | to find the name 'Purchase Agreement' which is written in one line on all of the documents, you need to enter PURCHASEAGREEMENT. |
Use a vertical line (the symbol '|') to separate variants.
| E.g.: | If similar documents may have such names as Contract or Agreement, you need to enter CONTRACT|AGREEMENT. |
Variants of phrases are enclosed in curly braces and separated by a vertical line: { }|{ }. You can list variants of words within phrases (the Take spaces into account option must be selected).
| E.g.: | If you enter {SALE|PURCHASE AGREEMENT|CONTRACT}|{CUSTOMER|CLIENT APPLICATION} in the Search text field, the program will look for the following phrases: sale agreement, purchase agreement, sale contract, purchase contract, customer application, client application. |
To enter long strings, click  which opens a separate data entry window.
which opens a separate data entry window.
- Search text from database
You can search for a text fragment from a database on your image. An SQL query starting with the SELECT command is used to search for the relevant fields in the table. The program will search on the image for the text contained in the found field. - Enter the data base connection string in the Connection string fields or click to open the standard database connection dialog box.
- Type your query in the Query text field. You can also click to open a separate data entry window where you can type in your query.
- Search text from file
You can search for a text fragment from a file. Click the Browse... button to select the desired file. For details about using databases and files, see Using databases and text files in the FlexiLayout language. - Max number of errors
- the maximum number of errors in the word. The program will check each word in the phrase if the words in the phrase are separated by spaces. Otherwise the phrase will be considered to consist of only one word. If the number of errors in a word is higher than the number specified in this field, the word is considered not detected. One error corresponds to one delete, paste, or replace operation required to adjust the text so that it corresponds to the text typed in the Search text field.
By default, the value of this property is unlimited.
| E.g.: | Suppose the Search text field contains the word 'meet' and the maximum number of errors is set to 1. If the program finds the word 'moot' in this search area, there will be 2 errors in the word and the word 'meet' will be considered not found. |
- Max error percentage
the maximum percentage of errors in the word (calculated as the ratio of the number of errors in the hypotheses to the number of letters in the hypothesis). If the percentage of errors in a word is higher than the percentage specified in this field, the word is considered not detected. The default value is 30%. Note.If you specify both the maximum number of errors and the maximum percentage of errors, the program will use the more strict criterion and ignore the other.
Note.If you specify both the maximum number of errors and the maximum percentage of errors, the program will use the more strict criterion and ignore the other. - Max space length
allows you to specify the maximum length of the space inside the detected object. - Whole words only
searches for whole words only. - Match case
enables case-sensitive search (the program distinguishes between small and capital letters). - Take spaces into account
allows spaces in the search string. If this option is not selected, spaces will be removed from the search string. Ignoring spaces makes the search faster. However, if your search phrase may be located on multiple lines or if some words in the phrase may be missing, you need to enable the Take spaces into account option and type in your search phrase preserving the spaces.
The following options are available only if Take spaces into account is selected:
- Permit multiple lines - allows the phrase to be written in several lines.
- Line break penalty - sets a penalty for line breaks words. The penalty is a number from 0 to 1. The quality of the hypothesis will be multiplied by this number as many times as there are line breaks in the phrase. If line breaks are allowed in the phrase, set this parameter to 1 (multiplying the quality of the hypothesis by 1 will not downgrade its quality).
- Permit missing words - allows missing words in the phrase.
- Missing word penalty - sets a penalty for missing words. The penalty is a number from 0 to 1. The quality of the hypothesis will be multiplied by this number as many times as there are missing words in the phrase. If some words may be absent in the phrase, set this parameter to 1 (multiplying the quality of the hypothesis by 1 will not downgrade its quality).
Recommendations on creating a Static Text element
Since static text is known in advance, a Static Text element can be used as a reference element to look for other image objects. Use the following guidelines:
- to make sure that the selected static text can be reliably recognized on all of the images, view the pre-recognition results on all of the images by clicking
 or
or  for words and phrases respectively. Make sure that the letters are correctly grouped into words and words are correctly grouped into lines.
for words and phrases respectively. Make sure that the letters are correctly grouped into words and words are correctly grouped into lines. - It is best to select static text printed in larger letters which remains the same even on poor quality scans or in which the number of OCR errors is predictable.
- If there is only small print static text on the documents which cannot be reliable recognized during pre-recognition (i.e. the number and types of errors are very different on different images), such text fragments are better described not as Static Text but as Object Collection with the Text and Punctuation mark options selected. (You may also need to select the Picture option - click
 (Raw Objects ) on the toolbar and select the corresponding object on the image. The type of the object will be displayed in the DataType line in the Properties window.)
(Raw Objects ) on the toolbar and select the corresponding object on the image. The type of the object will be displayed in the DataType line in the Properties window.) - It is preferable to select unique static text fragments so as to prevent wrong hits and to keep additional search constraints to a minimum.
- If there are both single-word names (which you plan to find by means of Static Text elements) and phrase names which contain the same words as single-word names, first create elements for the phrases. This will prevent the program from wrongly detecting single-word names within phrase names.
Recommendations for hieroglyphic languages
For strings in Chinese, Japanese and Korean languages, a special search parameter can be used. The parameter affects the method of counting the number of errors in the found hypothesis as compared with the specified value of the Search text element. If this parameter is enabled, then in operations of insertion/deletion/replacement a character which are counted as one error each, only characters (hieroglyphs) with similar tracing are allowed as replacement characters. Thus, replacing a character with a similar character is counted as one error, while replacing it with a dissimilar character is counted as two errors because of two performed operations which are deleting a character and inserting a new one.
Enabling this search mode affects search for strings in Chinese, Japanese and Korean languages only.
Note.For these languages, a whole word search is not available, because texts written in these languages are often not divided into words explicitly.
To enable this search mode, enter the following code into the Advanced pre-search relations pane of the Advanced tab:
SuggestOnlySimilarChars(Logic value = true);
By default the SuggestOnlySimilarChars parameter is set to false.
See also:
Creating and deleting elements
4/12/2024 6:16:02 PM