Using Group elements to optimize FlexiLayout structure and search
Using Group elements to search for objects is most efficient, because grouping elements together reduces the number of hypotheses for an element and speeds up the search for the resulting hypothesis for the whole FlexiLayout. Moreover, if the grouping of the elements reflects the logic of the document, it helps to optimize the structure of the FlexiLayout and makes it more explicit.
Grouping several elements together into one Group element enables the program to treat this set of elements as a whole with its own hypothesis (composed of individual hypotheses for elements in the group). Analysis of hypotheses and their elements takes place within the Group element, and only the user-specified number (1 by default) of the best hypotheses are used in the subsequent search for other elements.
The entire tree of elements can be regarded one Group element, the best hypothesis for which is the result of matching the FlexiLayout.
Let us study the GroupSample.fsp project (folder %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Group\Project1) to see how Group elements can be used. Here we have an image where we want to detect fields with the invoice number, the invoice date, and the invoice sum.

As is seen on the image (the same is usually true for all financial documents), the number and the date of the document are neighboring fields. Even if the arrangement of the fields on another document is different, they still will be close to each other. Furthermore, they are connected by the logic of the document, as they describe certain bank details and form a logical block. To make the structure of the FlexiLayout more explicit, we will group them into a Group element named InvoiceRequisiteGroup.
 Note.Prior to grouping the elements, we created a special identifying element. (Identifier elements are described in detail in the section "Identifying and Processing FlexiLayouts in ABBYY FlexiCapture".) This element was only created to illustrate the "branching out" of the tree of hypotheses caused by the presence or absence of Group elements in it. Let us assume that all the elements in the tree, except the identifier element, are optional, and their null hypotheses have the default quality of 0.97.
Note.Prior to grouping the elements, we created a special identifying element. (Identifier elements are described in detail in the section "Identifying and Processing FlexiLayouts in ABBYY FlexiCapture".) This element was only created to illustrate the "branching out" of the tree of hypotheses caused by the presence or absence of Group elements in it. Let us assume that all the elements in the tree, except the identifier element, are optional, and their null hypotheses have the default quality of 0.97.
The first element in the Group is an element of type Static Text, named InvoiceNumHeader, which describes the search constraints for the name of the field "Invoice number". The string "Invoice" is specified as the value of this element.
Based on the analysis of the images at our disposal, we will search for the invoice number to the right of the name, with the help of an element named InvoiceNum.
Similarly, under the line with the invoice number we created an element for the date field and named it InvoiceDateHeader. To search for the date itself we created the group DateGroup with the following subelements: InvoiceDate and InvoiceDateAsString. See Creating FlexiLayouts for poor quality images for more details.
To detect the field with the invoice sum, we created two elements: an element of type Static Text named TotalSumHeader (its value "Totalsum(EUR):" is written without spaces), and an element of type Character String named TotalSum (the latter will be used to look directly for the sum).
Note.We do not describe here the settings of the elements. You can look them up directly in the project.
Please note that the string "Invoice", specified as the value of the element InvoiceNumHeader, can be encountered on the test images three times: as the name of the field "Invoice number", as a substring of the name of the field "Invoice date", and at the bottom of the invoice, as a substring in the invoice conditions: "Current invoice is…". It is also important to note that the name "INVOICE" (which we are going to detect by means of the InvoiceNumHeader element) is very noisy, which caused an error in the name. In the other lines, the string "Invoice" is clear, and the quality of the corresponding hypotheses must be higher than that of the hypothesis for the name.
Now try matching the FlexiLayout with the test images in the batch.
Once you have started the FlexiLayout matching procedure by selecting the Match command, you will see that the tree of hypotheses consists of a single chain.
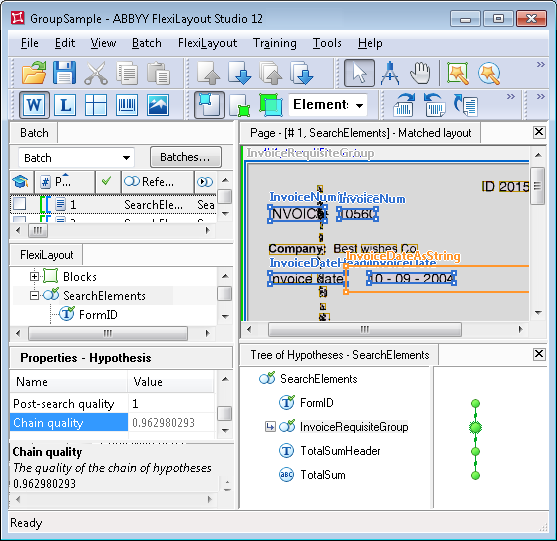
The tree of hypotheses consists of just one chain. The quality of the Group coincides with the quality of the best chain in the Group.
Double-click InvoiceRequisiteGroup to open its Properties dialog box where we can see what hypotheses were generated for its subelements, which chain in the Group turned out to be the best and why.
We see that there are three hypotheses for the InvoiceNumHeader element, equal to the number of "invoice" strings detected. The quality of the hypothesis we are interested in is lower (approximately 0.99), because its area on the image is noisy and the program could only recognize "INVOIC" instead of "INVOICE". The quality of the other two hypotheses, however, is maximum (Chain quality = 1).
At the creation of the InvoiceNum element we specified that the invoice number can have any number of digits and should be sought to the right of the name. On our image these conditions are met in all the three cases, which enabled the program to continue creating a chain of hypotheses for each of the hypothesis for the name of the "Invoice number" field. It should be noted that, in spite of the fact that the Pre-search quality of each of the hypotheses of the InvoiceNum element is 1, the chain that we consider to be correct is still the worst. This happened because chain quality is assessed by the multiplying the qualities of all the hypothesis forming the chain. For the required name this quality is about 0.99. If the Group did not have any other elements, the final choice at this stage would be incorrect.
Note.We did not specify Post-search relations for any of the elements, so for each of the elements Post-search quality = 1, and we can judge the quality of any given hypothesis by its Pre-search quality.
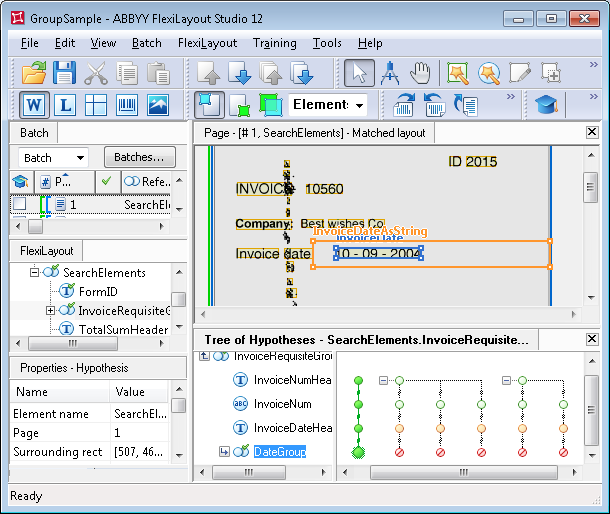
The search for the best hypothesis is done within the Group. The quality of all the chains is analyzed and compared. The quality of the Group will be determined by the quality of the best chain in the Group.
As we noted above, in the properties of the InvoiceDateHeader element we specified that it should be sought under the line with the invoice number. However, none of the chains with the best quality (Chain quality = 1) resulted in a hypothesis for the name of the date field. Consequently, null hypotheses were formed in these chains for the InvoiceDateHeader element. Since we did not change the default quality of a null hypothesis, the resulting Chain quality of the corresponding chains dropped to 0.97. At the same time, the element corresponding to the name of the date field was found for the chain that had the lowest quality. The quality of its hypothesis is approximately 0.993. It is less than 1 not because the image in the area of the name is noisy, which resulted in a recognition error and an incomplete match between the recognized text and the value specified in the properties of the InvoiceDateHeader element. As a result, the found hypothesis was penalized and its final quality is about 0.98 (the result of multiplying 0.99 by 0.993). Nevertheless, the final quality of this hypothesis is higher than that of the others (0.97), so at this stage this chain is the best.
To detect the date field, we created the Group element DateGroup, which specifies that at least one of the elements cannot be found if the other has been found (the Dontfind function was used). As a result of the document layout features and the properties specified for the InvoiceDateAsString element (its alphabet allows digits), the program managed to find the date field for all the chains, though only one hypothesis in the three is actually correct.
Since in each Group one of the elements has been found while the other has not, the final quality of the chain in each of the DateGroup groups is 0.97 (1 multiplied by 0.97, the default quality of the null hypothesis). In this example, the final quality of the DateGroup chains will not affect the "balance" among the hypotheses at the moment of detecting the InvoiceDateHeader element, i.e. the quality of each of the chains will be simply further multiplied by 0.97.
At the end the program generated a single hypothesis for the Group element InvoiceRequisiteGroup, which corresponds to the best chain in the Group. Its quality is approximately 0.953, i.e. the "group approach" helped the right hypothesis win, even though its initial quality was lower.
To illustrate how the tree of hypotheses would look like without Group elements in the FlexiLayout, we created the GroupSample.fsp project (Group\Project2 folder). The tree can be seen in the figure below. As is clear from the figure, after detecting the FormID element, the tree of hypotheses branched out because several hypotheses are generated for the InvoiceNumHeader element. As a result, the program has to compare the qualities of each of the chains, starting every time from its very first element and moving down to the last. Moreover, for any document with a layout more complex than the one in this example, a FlexiLayout without Group elements will produce a tree of hypotheses with too many branches, which will make FlexiLayout matching more difficult.
Note.It is not recommended to place all the sought elements into one root group. This is only suitable for very simple FlexiLayouts with fewer than 10 elements, which is very rare in real-life tasks. An increase in the number of elements in the root Group causes massive growth of the number of hypothesis, until it reaches its limit of 10,000 or the memory allocated for the tree of hypotheses is all used up. In either case, matching the FlexiLayout may fail.
In real-life tasks there is usually no need to explore all the possible combinations of every hypothesis for one element with every hypothesis for every other element, as most of the elements might be detected independently from one another. That is why it is advisable to Group elements into the smallest possible Group elements, so as to reduce the number of combinations to analyze and speed up the search.
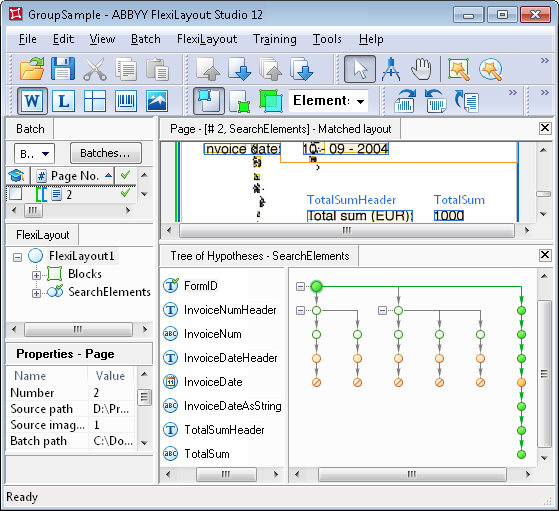
An ungrouped tree of hypotheses has too many branches and its visual analysis is difficult.
Moreover, since the quality of the final chain is calculated by multiplying the qualities of all the hypotheses in that chain, the volume of calculations may be much higher in a tree with too many branches, which will results in slower FlexiLayout matching.
4/12/2024 6:16:02 PM