Setting multiple static text values. Search for static text with similar values
To detect various titles of documents, tables, fields, or any text present on all or most of the images in a document, FlexiLayout Studio uses a special Static Text element. If different images which are to be processed by means of the same FlexiLayout have different variations of one and the same name (for example, the field 'Invoice number' has variations 'Invoice', 'Invoice:', 'Invoice No.', etc.), you must specify all the possible static text values even if they only differ in punctuation marks.
This is necessary due to the following reasons:
- To generate a hypothesis corresponding to the specified value. For example, if we do not specify the variant 'Invoice:' but only specify the variant 'Invoice', the colon will not be included into the hypothesis for the field name. It may then be included into the search area of the invoice number which the program will search to the right of the name. If the search for the number allows non-digit or non-specified characters, then the column may get into the hypothesis of the element that describes the invoice number.
- To avoid penalizing a hypothesis for characters not specified in the Search text window. For example, if the value 'Invoice:' is specified in the Search text section and the name 'Invoice#' is also encountered on the processed images, then, provided that some errors are permitted for the element, a hypothesis will still be generated but its quality will be penalized (in this example the FlexiLayout allows at least 1 error).
- If there are variant hypotheses available, for example, 'Invoice|Invoice:', the program will assign the longer hypothesis a slightly higher quality, so that the hypothesis 'Invoice:' will be preferable. If a variant with ':' is specified, then the one without ':' will be penalized by 0.001, because the string 'Invoice' is a sub-string of 'Invoice:'. Penalizing the shorter name string, which is a sub-string of the other, makes the longer hypothesis the winner.
Let us use the sample project StaticText.fsp (folder %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Variants of StaticText) to see how specifying the values of a Static Text element helps to detect the name of the 'Invoice number' field and the field itself.
The project has 5 pages:
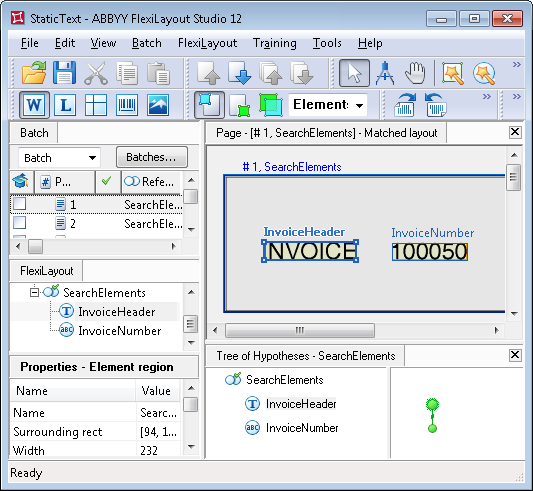
- Page 1 - the field "Invoice number" has the name "INVOICE";
- Page 2 – the field "Invoice number" has the name "Invoice:";
- Page 3 – the field "Invoice number" has the name "Invoice #:";
- Page 4 – the field "Invoice number" has the name "Invoice -";
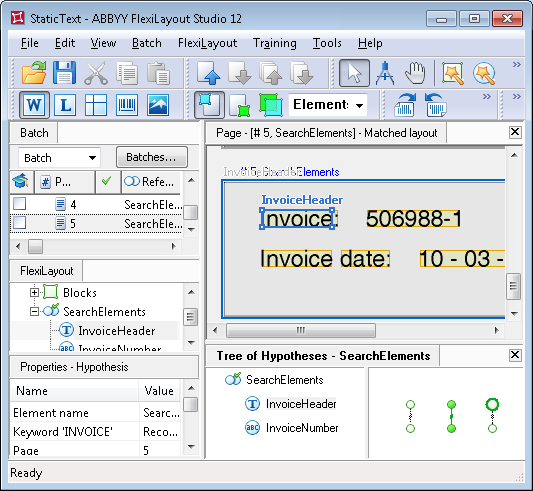
- Page 5 – the field "Invoice number" has the name "Invoice:", but the page also has a field "Invoice date", where the word "Invoice" is present.
In the Properties dialog box of the Static Text element named InvoiceHeader, we have specified all the possible names for the field that may be found on the processed documents. In this case, these are the above mentioned values. Letter-case in the names is irrelevant for search purposes: Invoice|Invoice:|Invoice#:|Invoice-.
 Note.To speed up the search for the element, all the variants are written without spaces. Absence or presence of spaces does not influence the quality of a hypothesis.
Note.To speed up the search for the element, all the variants are written without spaces. Absence or presence of spaces does not influence the quality of a hypothesis.
For the sake of simplicity, let us assume that the invoice number is always located to the right of the name. To search for the invoice number, a Character String element named InvoiceNumber has been created. Its alphabet and search constraints are specified in the Relations field. These settings are very simple and are not described here. You can look them up directly in the project.
A text block Invoice has been created in the FlexiLayout tree. The element InvoiceNumber has been specified as the Source element for the block.
As you can see after running the analysis procedure, the field name and the invoice number can be successfully detected on all the pages.
Now try removing temporarily all the static text values but the first (Invoice) from the InvoiceHeader element, and then try matching the FlexiLayout with all the pages again. You will see that the name and the invoice number have been successfully detected only on Page 1, because the name there fully matches the specified value (Invoice). On Pages 2-4, a part of the name got into the invoice number. On Page 5, there was an error in locating the number field.
Let us now restore the removed values. Look at the analysis results on Page 5, where the word Invoice occurs twice. As can be seen, the program generated 5 hypotheses for the InvoiceHeader element. The highest quality (Chain quality = 1, which, in this case, is equal to the Pre-search quality) is assigned to the hypothesis for the name "Invoice:". Hypotheses were also generated for the values "Invoice" and "Invoice d", because these strings are derivatives of the values specified for the InvoiceHeader element, for which a certain percentage of errors is allowed. These hypotheses were penalized (Cf. the above arguments for listing all the possible Static Text values), so their final quality is lower.
4/12/2024 6:16:02 PM