グループ要素を使用したFlexiLayoutの構造と検索の最適化
オブジェクト検索にグループ要素を使用すると効率的です。グループ要素を一緒に使用すると、要素の仮説数が減少し、FlexiLayout全体の結果として生じる仮説の検索速度が上がるためです。さらに、要素のグループ化が文書の論理を反映している場合、FlexiLayoutの構造を最適化し、より明示的にするのに役立ちます。
複数の要素を1つのグループ要素にグループ化することで、この要素のセットを独自の仮説(グループの要素の個々の仮説から構成)で扱うことができます。仮説とその要素の分析は、グループ要素内で行われ、最善の仮説のユーザー指定番号(デフォルトで1)のみが、後続の他の要素の検索で使用されます。
要素のツリー全体を1つのグループ要素と見なすことはできますが、FlexiLayoutを合致させた結果が最善の仮説です。
グループ要素がいかにして使用されるかを学ぶために、GroupSample.fspプロジェクトを見ていきましょう(フォルダ%public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Group\Project1)。ここには、請求書番号、請求日、請求書合計のフィールドを検出する画像があります。

画像の通り(すべての財務文書で一般的)、文書の番号と日付は隣接フィールドです。別の文書のフィールドの配置が異なっていても、依然として互いに近くにあります。さらに、文書の論理によって連結します。これらは特定の銀行情報の詳細を記述し、論理ブロックを形成するためです。FlexiLayoutの構造をより明示的にするために、InvoiceRequisiteGroupと名付けたグループ要素にグループ化します。
 注意:要素をグループ化する前に、特別な識別要素を作成しました。(識別子要素はセクション「ABBYY FlexiCaptureでのFlexiLayoutsの識別と処理」に詳細に記載されています)。 この要素は、グループ要素の有無によって引き起こされる仮説ツリーの「枝わかれ」を示すためだけに作成されました。識別子要素を除く、ツリーのすべての要素はオプションで、その帰無仮説にはデフォルトの質0.97があるとします。
注意:要素をグループ化する前に、特別な識別要素を作成しました。(識別子要素はセクション「ABBYY FlexiCaptureでのFlexiLayoutsの識別と処理」に詳細に記載されています)。 この要素は、グループ要素の有無によって引き起こされる仮説ツリーの「枝わかれ」を示すためだけに作成されました。識別子要素を除く、ツリーのすべての要素はオプションで、その帰無仮説にはデフォルトの質0.97があるとします。
グループの最初の要素は、種類静的テキストの要素で名前はInvoiceNumHeaderです。これはフィールド「請求書番号」の名前に対する検索制限を記述します。文字列「請求書」はこの要素の値として指定されています。
画像の分析に基づいて、InvoiceNumと名付けられた要素を使い、名前の右にある請求書番号を検索します。
同様に、請求書番号の行の下に、日付フィールドの要素を作成して名前をInvoiceDateHeaderと付けました。日付自体を検索するために、以下のサブ要素のあるグループDateGroupを作成しました:InvoiceDateおよびInvoiceDateAsString。詳細は質の悪い画像でのFlexiLayoutsの作成をご覧ください。
請求書合計のフィールドを検出するために、2つの要素を作成しました: 種類静的テキストの要素で名前はTotalSumHeader(値「Totalsum(EUR):」にはスペースなし)および種類文字列の要素で名前はTotalSum(後者は合計を直接見るのに使用)。
注意:ここでは要素の設定の説明は省きます。プロジェクトで調べることができます。
要素InvoiceNumHeaderの値として指定されている文字列「請求書」は、試験画像に3回出てくる可能性があります: フィールド「請求書番号」の名前として、フィールド「請求日」の名前のサブ文字列として、請求書の下部で、請求条件のサブ文字列として:「現在の請求書は…」。名前「請求書」(InvoiceNumHeader要素で検出しようとしている)にはノイズが多く、名前でエラーが発生することに注意してください。他の行では、文字列「請求書」ははっきりし、対応する仮説の質は、その名前の仮説の質よりも高いはずです。
FlexiLayoutをバッチの試験画像と合致させてみてください。
合致コマンドを選択してFlexiLayout合致手順を始めると、仮説ツリーが単一鎖で構成されていることがわかります。
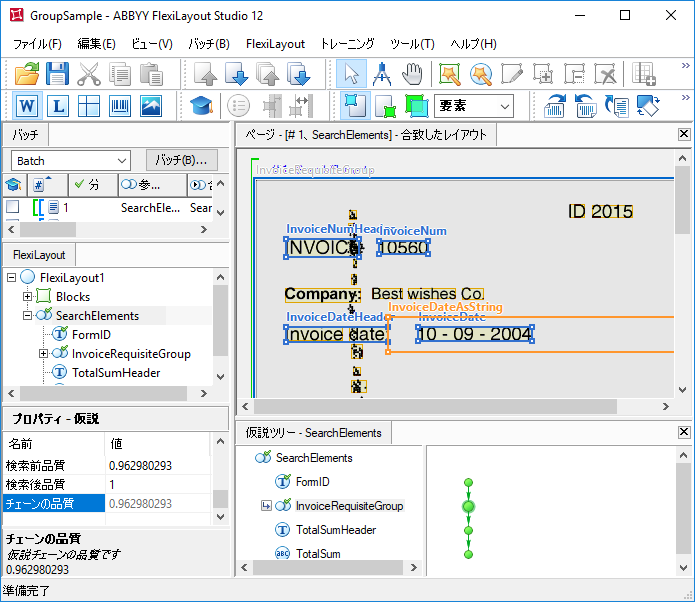
仮説ツリーが単一鎖で構成されています。グループの質は、グループの最高の鎖の質と一致します。
InvoiceRequisiteGroupをダブルクリックして、そのプロパティダイアログボックスを開くと、どの仮説がそのサブ要素で生成されているのか、グループのどの鎖が最善だったのか、なぜか、がわかります。
検出された「請求書」文字列の数に等しいInvoiceNumHeader要素の仮説が3つあることがわかります。関心対象の仮説の質は低いです(約0.99)。画像の領域にノイズが多く、「INVOICE」ではなく、「INVOIC」しか認識できないためです。でも、他の2つの仮説の質は最大です(連鎖品質 = 1)。
InvoiceNum要素の作成時に、請求書番号には任意の桁数があり、名前の右で検索されるよう、指定しました。画像では、これらの条件はすべての3つのケースで満足され、「請求書番号」フィールドの名前の各仮説で仮説連鎖が作成され続けました。InvoiceNum要素のそれぞれの仮説の検索前品質が1であるという事実にもかかわらず、正しいと見なしている連鎖は依然として最悪であることに注目してください。連鎖品質に連鎖を形成するすべての仮説の質を乗算して評価されるため、これが起こりました。必要な名前では、この質は約0.99です。グループに他の要素がない場合、この段階での最終的な選択は間違っています。
注意:どの要素でも検索後関係を指定しなかったため、各要素検索後品質 = 1では、仮説の質をその検索前品質で判断できます。
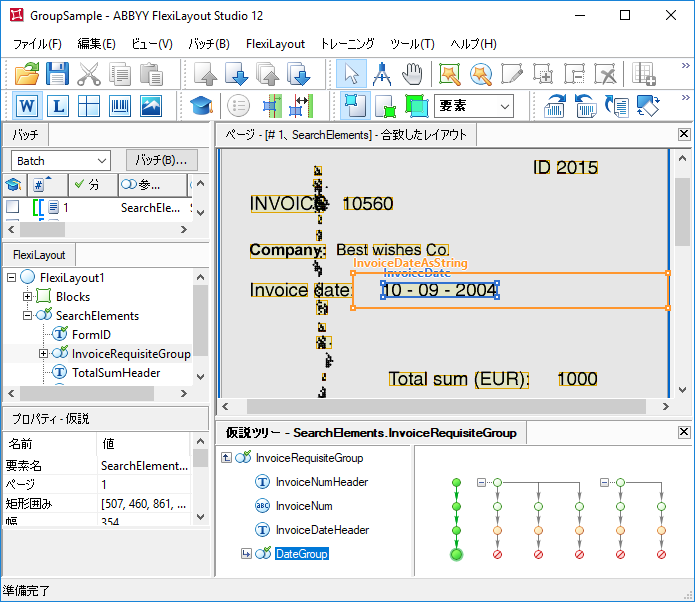
最善の仮説の検索は、グループ内で行われます。すべての連鎖の質が分析、比較されます。グループの質は、グループの最善の鎖の質で割り出されます。
上記の通り、InvoiceDateHeader要素のプロパティで、請求書番号の行の下で検索されるよう、指定しました。しかしながら、最良品質(チェーンの品質 = 1)のどの連鎖も、日付フィールドの名前の仮説を結果として出しませんでした。従って、帰無仮説がInvoiceDateHeader要素のこれらの連鎖で形成されました。帰無仮説のデフォルト品質を変更しなかったため、対応する連鎖の結果チェーンの品質は0.97に低下しました。同時に、日付フィールドの名前に対応する要素が、最も質の低い連鎖で検出されました。その仮説の質は約0.993です。これは1未満です。これは名前の領域の画像にノイズが多く、認識エラーを引き起こし、認識されたテキストとInvoiceDateHeader要素のプロパティで指定された値の不完全な合致を引き起こしたからではありません。結果として、発見された仮説にはペナルティが科され、最終的な質は約0.98でした(0.99に0.993を乗算)。これにもかかわらず、この仮説の最終的な質は他(0.97)より高いので、この段階ではこの連鎖が最善です。
日付フィールドを検出するために、グループ要素DateGroupを作成しました。これは、他の要素が見つかった場合に、少なくとも1つの要素が見つからないよう、指定するものです(Dontfind関数使用)。文書のレイアウト機能とInvoiceDateAsString要素(そのアルファベットが数字を許容)で指定されたプロパティの結果として、すべての連鎖の日付フィールドが検索されましたが、実際には3つの仮説のうち1つの仮説が正しいだけです。
各グループで1つの要素が見つかり、別の要素が見つからなかっため、各DateGroupグループの連鎖の最終的な質は0.97です(帰無仮説のデフォルト品質として1に0.97を乗算)。この例では、DateGroup連鎖の最終的な質はInvoiceDateHeader要素の検出時には仮説の間の「バランス」に影響を及ぼしませんでした。つまり、各連鎖の質は以降、0.97で乗算されるだけです。
最後に、グループの最善連鎖に対応する、グループ要素InvoiceRequisiteGroupで単一仮説が生成されました。この品質は約0.953すなわち初期の質が低いにもかかわらず、「グループアプローチ」で正しい仮説の勝利が促されました。
仮説ツリーがFlexiLayoutでグループ要素なしにどう見えるかについて、GroupSample.fspプロジェクトを作成しました(Group\Project2 フォルダ)。ツリーは下の図の通りです。図の通り、FormID要素検出後、仮説ツリーは枝わかれしました。複数の仮説がInvoiceNumHeader要素で生成されたためです。結果として、最初の要素から最後の要素へと下がりながら、各連鎖の質が比較されなければなりません。また、この例よりも複雑なレイアウトの文書では、グループ要素のないFlexiLayoutは、枝の多すぎる仮説ツリーを生成し、FlexiLayoutの合致を難しくします。
注意:求められる要素をすべて1つのルートグループに入れることはおすすめしません。これは要素が10個未満の簡単なFlexiLayoutsにしか適していません。これは実際のタスクではまれです。ルートグループの要素数が増えると、仮説数は限度の1万に達するまで、または仮説ツリーに割り当てられたメモリが使い尽くされるまで、増加していきます。どちらの場合でも、FlexiLayoutの合致は失敗する可能性があります。
通常、1つの要素に対するそれぞれの仮説とそれぞれの他の要素のそれぞれの仮説の可能なすべての組み合わせを探る必要はありません。要素のほとんどは独立して検出されるためです。要素を可能な限り最小限のグループ要素にグループ化することが推奨されるのは、このためです。分析する組み合わせの数を減らせば、検索のスピードを上げられます。

グループ化されていない仮説ツリーに枝が多すぎると、視覚的分析が困難です。
また、最終連鎖の質はその連鎖のすべての仮説の質を乗算して計算されるため、枝が多すぎるツリーでは計算量が非常に多くなり、FlexiLayoutの合致が遅くなります。
12.04.2024 18:16:07