数字列の検索
種類文字列の要素は数字列の検索に使用されます。画像の質がとても良好な場合、正規表現でもアルファベットとして指定することができます。ですが、バッチの画像の質が異なる場合は、対応するフィールドで認識できる文字のリストを指定する必要があります。画像の質や印刷の質が満足いくものでない場合、数字は他の文字として間違って認識される可能性があります。例えば、「8」が「B」、「7」が「?」、「5」が「S」、「4」が「H」や文字の組み合わせ「LI」などと認識されたりします。これは、数字が「接着」している場合に発生します。文書がタイプライターで書かれている場合に一般的です。
認識結果と実際の文字の一致度は、画像の質によって変わります。処理された画像のすべてまたは大部分で文字が誤解釈される傾向がある場合は、対応する要素文字列のアルファベットを編集ウィンドウのアルファベットにこれらの認識バリエーションを追加する必要があります。これらの文字を指定して、検索領域にこれらの文字があっても仮説にペナルティを科さないよう指示します。
 注意:可能なすべての認識バリエーションを用意する必要はありません。画像の質が悪い場合、バリエーションをすべて見つけるのは極めて手間のかかる作業です。画像の質が低くて認識結果が予測できない場合は、文字列の長さ、文字列のスペースの長さなどの他の要素のプロパティを使用して検索します。
注意:可能なすべての認識バリエーションを用意する必要はありません。画像の質が悪い場合、バリエーションをすべて見つけるのは極めて手間のかかる作業です。画像の質が低くて認識結果が予測できない場合は、文字列の長さ、文字列のスペースの長さなどの他の要素のプロパティを使用して検索します。
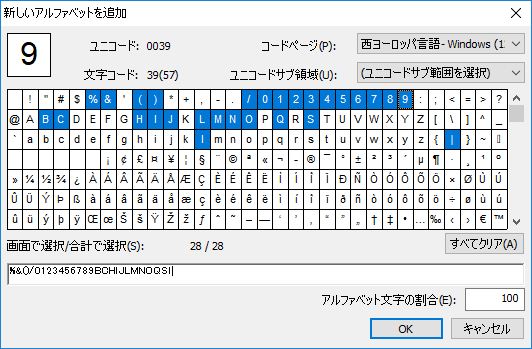
外形が数字に似ている文字を指定します。このような文字が誤認識される可能性は、残りの文字よりも高いです。必要に応じて、一般的に数字と誤認識されやすい他の文字も指定できます。
プロジェクト1.fspを考察しましょう(フォルダDigital strings\Project1)。
プロジェクトには3ページあります。
- ページ1 – 数字4は文字の組み合わせ「LI」として認識;
- ページ2 – サブ文字列13は文字「å」として認識;
- ページ3 – 数字0は「a」、2と5は「S」、6と8は「B」として認識。
数字列を検出するために、種類文字列の要素を作成して名前をDigitalStringと付けて数字のみをそのアルファベットとして指定しました。非数字文字の最大割合を20に設定しました。
すべてのページでFlexiLayoutの合致を実行した後、ページ3の数字フィールドはまったく検出されませんでした。仮説の品質値は約0.98です。ページ1と2で、文字列が検出されました。ですが、非アルファベットの文字が含まれているため、対応する仮説にはペナルティが科され、その質はそれぞれ0.978と0.982になりました。
数字と認識されなかった文字をアルファベットに追加する場合の、FlexiLayoutの合致結果を見てみましょう:L, I, e, a, B, S.
FlexiLayoutの合致結果はプロジェクト2.fspで閲覧可能です(フォルダ %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Digital strings\Project2)。
プロジェクトの他の設定は同じです。
表示の通り、ページ3の文字列は完全に検出されており、生成されたすべての仮説の質は1です。
4/12/2024 6:16:07 PM