異なるOCR質の文書で既知または未知の形式の単一行フィールドを検索
単一行フィールドを検出するために、FlexiLayout Studioには特別な文字列要素があります。求められるフィールドに既知の形式がある場合、正規表現フィールドの文字列タブの対応する要素のプロパティで記述することができます。しかしながら、正規表現を使用すると、フィールドでのエラー発生が許容されないため、印刷された文書と良好な画質が要求されます。そうでなければ、要素は検出されません。文書が手書きされている場合は、文書のレイアウトが記述可能であっても、正規表現を使用しないでください。それでも、このようなフィールドは検出することができます。
すべてのページで類似形式の単一行フィールド「請求書番号」を検索することは、サンプルプロジェクトStructuredStrings.fspに示されています(フォルダ%public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Structured strings)。
プロジェクトには4ページあります:
- ページ1と2 - フィールド「請求書番号」がプリンタで入力され、印刷品質は良好;
- ページ3 – フィールド「請求書番号」がプリンタで入力され、画像にはノイズが多い;
- ページ4 – 画像の質は良好だがフィールド「請求書番号」が手書き。
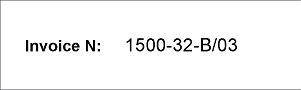 |
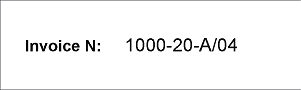 |
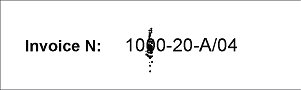 |
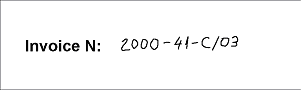 |
フィールド名を頼ってフィールド「請求書番号」を探します。まず、フィールド名の検索制限を記述する要素を作成します。作成された要素は、種類静的テキストの要素で、名前はInvoiceNumberHeader、値は「InvoiceN:」です。
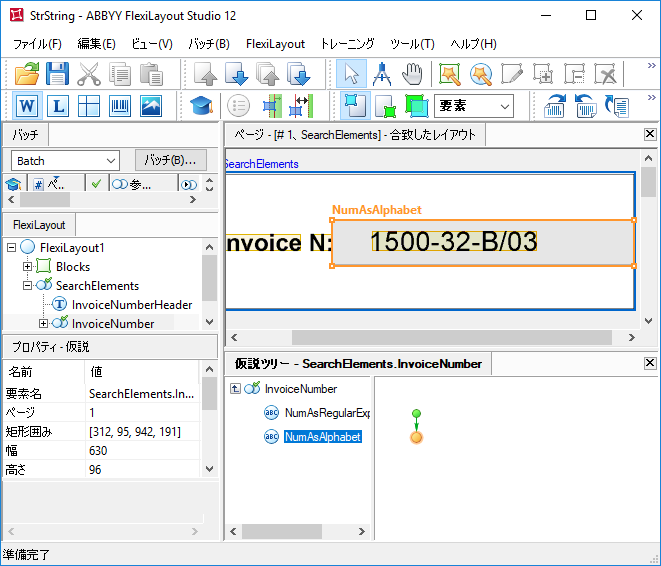
フィールド「請求書番号」は単一行フィールドです。これを検出するために、種類文字列の、名前NumAsRegularExpressionの要素を作成しました。プロジェクトのページの通り、フィールド「請求書番号」の形式は、以下の正規表現で記述することができます:
NNNN"-"NN"-"[A-Z]"/"NN
または(同じ)
[0-9]{4}"-"[0-9]{2}"-"[A-Z]"/" [0-9]{2}
これは数がシーケンスであることを意味します:"four digits - two digits - one Latin capital letter/two digits".
プロジェクトの通り、合致コマンドを選択してFlexiLayoutの合致を実行した後、ページ3と4で要素NumAsRegularExpressionに対して帰無仮説が生成されました、つまり、要素は検出されませんでした。ページ3で、ノイズがフィールドと正規表現の不一致を引き起こしました。ページ3を開いて、ツールバーで「L」(「認識された行を表示」)をクリックすると、請求書番号の事前認識は「10&0-20-A/04」のようになります。ページ4では、請求書番号が手書きです。事前認識結果(Z.OOO-41-C/03)で、記述された形式と合致しないことがわかります。
この問題には以下の解決策をおすすめします。名前NumAsAlphabetの種類文字列の要素をもう1つ作成します。NumAsRegularExpression要素と同じ検索制限を指定します。次に、2つの要素を1つのグループ要素InvoiceNumberにグループ化します。要素NumAsAlphabetは正規表現としては記述せず、有効なすべての文字のリストとして記述します。
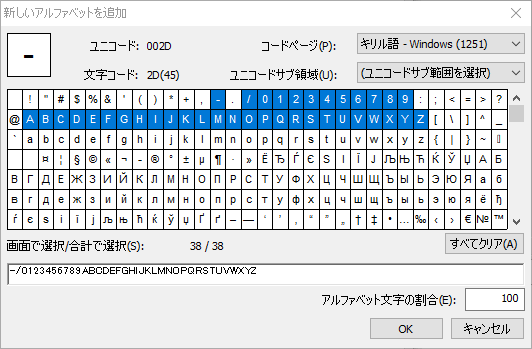
以下のコードを高度な検索前関係フィールドで書きます:
if (NumAsRegularExpression.IsNull == FALSE) then Dontfind();
これは、要素NumAsAlphabetで記述された未知の形式の文字列の検索が、固定形式の文字列を記述するNumAsRegularExpression要素で検出できなかった場合にのみ、試行されます。
 注意:NumAsAlphabet要素の検索制限を指定する時、ドラッグ・ドロップ方法で、設定を要素NumAsRegularExpressionのセクション関係から現在の要素の同じセクションへコピーすることができます。または、以下のコードを高度な検索前関係フィールドに書きます:
注意:NumAsAlphabet要素の検索制限を指定する時、ドラッグ・ドロップ方法で、設定を要素NumAsRegularExpressionのセクション関係から現在の要素の同じセクションへコピーすることができます。または、以下のコードを高度な検索前関係フィールドに書きます:
if (NumAsRegularExpression.IsNull == FALSE) then Dontfind();
else RestrictSearchArea (NumAsRegularExpression.Rect);
このコードの意味は、要素NumAsAlphabetの検索が、請求書番号の構造が指定形式に合致しないすなわち要素NumAsRegularExpressionが検出できなかった場合にのみ、試行されるというものです。要素NumAsAlphabetは、要素NumAsRegularExpressionが発見されなかった領域と同じ領域で検索されます。
すべてのページでFlexiLayoutの合致を再開します。プロジェクトの通り、各ページで請求書番号フィールドが正常に発見されました。
プロジェクトツリーでは、名前InvoiceNumのテキストブロックを作成しました。グループSearchElements。InvoiceNumberはそのソース要素として指定されます。この段階で、「請求書番号」フィールドを検出するためのFlexiLayoutの作成は完了です。
注意:何らかの理由で、上記の方法がデータフィールドを検出するのに十分でない場合(その形式が既知であっても未知であっても)、もう1つの要素(種類オブジェクト収集の)をグループで作成できます。このプロジェクトでは、種類オブジェクト収集の要素、名前はNumAsObjectCollectionです。プロジェクトの質の良い画像は実際には必要ではなく、例として示されているだけです(これに無効化コマンドが指定されています)。異なるページの事前認識結果を予測することが困難な時は、種類オブジェクト収集の追加要素を入れることが必要になってくるかもしれませんが、検索領域を正確に記述して不要な情報が仮説に入らないようにします。
以下の疑問が生じます: フィールドが正規表現なしで検出可能な場合もあるのに、なぜ正規表現が必要なのか?答えは、正規表現を使用すると検索の信頼性が高まる、です。この要素が見つかった場合は、必要な行が見つかったとわかります。次にこの情報を安全に使用して、さらなる要素とその関係を検出することができます。検索制限が緩いと、必要なものが見つかったと確信できません。
これは、画像にノイズが多い場合に発生する可能性があります。このような場合、指定したアルファベットのある種類文字列の要素を使用すると、エラー割合(非アルファベット文字の割合パラメータ)が非常に高くなります。結果として、要素はまったく検出されないか、部分的にしか検出されません。このような状況を下に図示します。
12.04.2024 18:16:07