Hypotheses and trees of hypotheses
A hypothesis is an assumption made by the program that the detected object(s) correspond(s) to a particular element, i.e. meet(s) the properties and search criteria specified for the element.
 Important!There may be several objects or sets of objects in the element’s search area, all of which correspond to the element. In this case, the program will formulate a hypotheses for each detected object.
Important!There may be several objects or sets of objects in the element’s search area, all of which correspond to the element. In this case, the program will formulate a hypotheses for each detected object.
Hypotheses are characterized by their quality.
The quality of a hypothesis measures how well the detected object matches the description contained in the corresponding element and is a numerical value from 0 to 1.
The quality of a hypothesis is calculated as [ Pre-search quality ]*[ Post-search quality ], where
- Pre-search quality is the quality of the settings made in the Properties dialog box and in the Advanced pre-search relations field
- Post-search quality is the result of applying the conditions specified in the Advanced post-search relations field.
The quality of a hypothesis for a Group element is calculated by multiplying the qualities of the hypotheses for all the constituent elements.
For optional elements the program formulates a null hypothesis.
A null hypothesis is a hypothesis which the program formulates if it has detected no objects corresponding to an optional element in the search area.
This means that if the program does not find any objects corresponding to an optional element, it does not stop matching the FlexiLayout, but formulates a null hypothesis and assigns it a quality set by the user when creating the optional element.
For the sake of convenience, we use the term hypothesis to refer to the set of objects included in a particular hypothesis.
Hypotheses: a practical example
Suppose we need to create two elements which will be used to find two static texts on our images. The first static text is "mother", the second static text is "father", and we know that the text "father" is always located below the text "mother" The first Static Text element, StaticText1, will be used to look for the text "mother", and the second Static Text element, StaticText2, will be used to look for the text "father". We assume also that both elements are optional and the quality of the null hypotheses for each of them is set to 0.97.
We will not set any constraints on the search area for StaticText1. As we know that the text "father" is always located below the text "mother", we can specify that StaticText2 must be always located below StaticText1. We will do this by typing the corresponding constraint on the Relations tab in the Properties dialog box of the StaticText2 element: Below: SearchElements.StaticText1;.
The figure below displays the results of matching the FlexiLayout with an image on which the word "mother" occurs twice (above and below the word "father") and one OCR error has been made in the word "mother" located above the word "father".
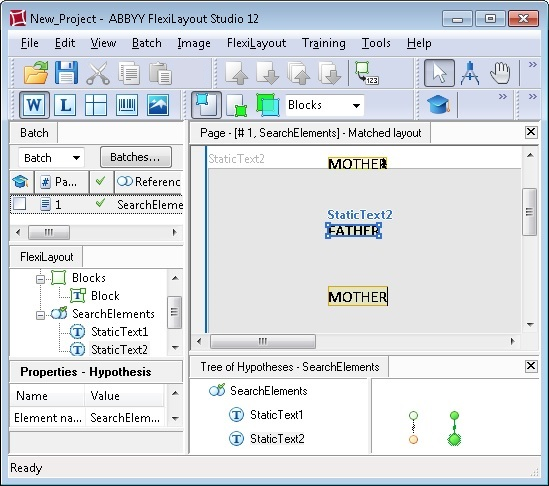
Matching the FlexiLayout has generated two hypotheses for the StaticText1 element. The first hypothesis corresponds to the word "mother" recognized with one OCR error and located above the word "father" and has a quality of 0.98. The second hypothesis corresponds to the word "mother" located below the word "father" and has a quality of 1.
At this stage, the quality of each chain is the same as the quality of the corresponding hypothesis. Therefore, the best chain consists of the hypotheses with a quality of 1.
Since we told the program to look for the StaticText2 below the StaticText1 element and since the program has generated two hypotheses for the StaticText1 element, now it is trying to find the required static text in two search areas. If the program pursues the second hypothesis with a quality of 1, which has found the word "mother" below the word "father", it will fail to find the StaticText2 element below the StaticText1 element and, consequently, it will generate a null hypotheses with a quality of 0.97. The quality of the resulting chain of hypotheses will be 1x0.97=0.97
If the program pursues the first hypothesis with a quality of 0.98, which has found the word "mother" above the word "father", it will successfully detect the StaticText2 element below the StaticText1 element and generate a hypothesis with a quality of 1. The quality of the resulting chain of hypotheses will be 0.98x1=0.98.
As a result, the program selects the chain with an overall quality of 0.98.
12.04.2024 18:16:02