Searching for single-line fields of known or unknown format on documents of varying OCR quality
To detect single-line fields, FlexiLayout Studio has a special Character String element. If the sought field has a known format, then it can be described in the properties of the corresponding element on the Character String tab in the Regular expression field. But the use of a regular expression demands printed documents and a good image quality, because description with a regular expression does not permit any errors to be made in the field, otherwise the element simply will not be detected. Regular expressions also must not be used if the document is filled in by hand, even if its layout can be described. Nevertheless, such a field can be detected.
The search for a single-line field "Invoice number" with a similar format on all the pages is shown in sample the project StructuredStrings.fsp (folder %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Structured strings).
The project has four pages:
- Pages 1 and 2 - the field "Invoice number" is filled in by means of a printer, printing quality is good;
- Page 3 – the field "Invoice number" is filled in by means of a printer, the image is noisy;
- Page 4 – the image quality is good, but the field "Invoice number" is filled in by hand.
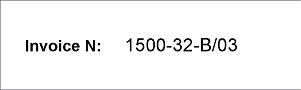 |
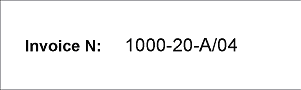 |
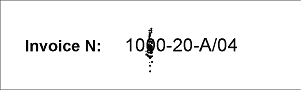 |
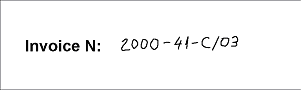 |
We are going to look for the field "Invoice number" relying on the field name. First we need to create an element describing the search constraints of the field name. The created element is of type Static Text, named InvoiceNumberHeader and has the value "InvoiceN:".
The field "Invoice number" is a single-line field. To detect it, we have created an element of type Character String, named NumAsRegularExpression. As can be seen on the pages of the project, the format of the field "Invoice number" can be described with the following regular expression:
NNNN"-"NN"-"[A-Z]"/"NN
or (which is the same)
[0-9]{4}"-"[0-9]{2}"-"[A-Z]"/" [0-9]{2}
It means that the number is a sequence: "four digits - two digits - one Latin capital letter/two digits".
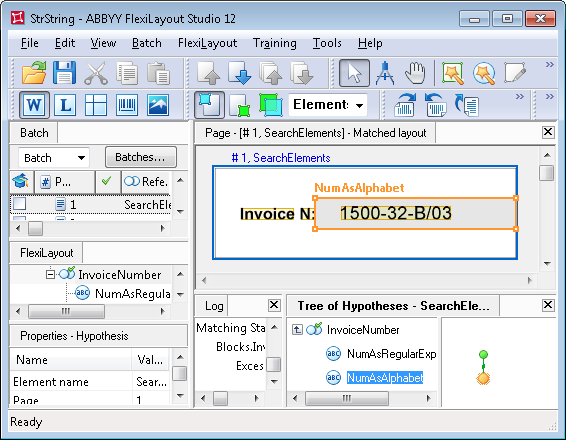
As is seen in the project, after running the FlexiLayout matching procedure by selecting the Match command, null hypotheses were generated for the element NumAsRegularExpression on pages 3 and 4, i.e. the element was not detected. On page 3, the noise caused a mismatch of the field and the regular expression. If you open Page 3 and click "L" ("Show Recognized Lines") on the toolbar, the pre-recognition of the invoice number on the page will look like "10&0-20-A/04". On Page 4, the invoice number is filled in by hand. You can see in the results of pre-recognition (Z.OOO-41-C/03) that it does not match the described format either.
The following solution to this problem is recommended. We create one more element of type Character String and named NumAsAlphabet. We specify for it the same search constraints as for the NumAsRegularExpression element. Then we group the two elements into one Group element InvoiceNumber. But we describe the element NumAsAlphabet not as a regular expression but as a list of all valid characters.
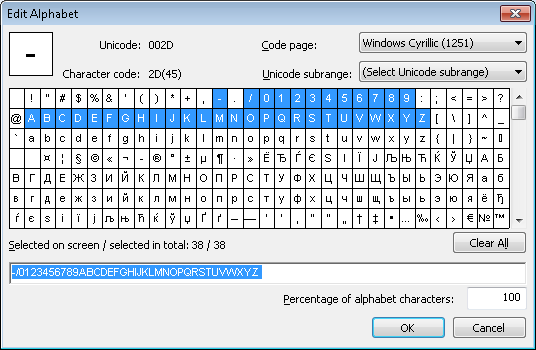
The following code should be written in the Advanced pre-search relations field:
if (NumAsRegularExpression.IsNull == FALSE) then Dontfind();
This means that the search for a string of an unknown format, described by the element NumAsAlphabet, will only be attempted if the program fails to detect it by means of the NumAsRegularExpression element, which describes a string of fixed format.
 Note.When specifying search constraints for the NumAsAlphabet element, you can use the drag&drop method to copy the settings from the section Relations of the element NumAsRegularExpression into the same section of the current element. Alternatively, the following code can be written in the Advanced pre-search relations field:
Note.When specifying search constraints for the NumAsAlphabet element, you can use the drag&drop method to copy the settings from the section Relations of the element NumAsRegularExpression into the same section of the current element. Alternatively, the following code can be written in the Advanced pre-search relations field:
if (NumAsRegularExpression.IsNull == FALSE) then Dontfind();
else RestrictSearchArea (NumAsRegularExpression.Rect);
This code means that a search for the element NumAsAlphabet will only be attempted if the structure of the invoice number doesn't match the specified format, i.e. the program failed to detect the element NumAsRegularExpression. And the element NumAsAlphabet will be looked for in the same area where the element NumAsRegularExpression wasn't found.
Now we start again the FlexiLayout matching procedure on all the pages. As is seen in the project, the invoice number field is now successfully found on each of the pages.
In the project tree we created a text block named InvoiceNum. The group SearchElements.InvoiceNumber is specified as its Source element. At this stage the creation of a FlexiLayout to detect "Invoice number" fields is complete.
Note.If, for some reason, the method described above is not sufficient for detecting the data field (whether its format is known or unknown), then one more element (of type Object Collection) can be created in the group. In this project, it is the element of type Object Collection, named NumAsObjectCollection. It is not actually needed given the good quality of the images in our project and is only shown as an example (the Disable command is specified for it). Introduction of an additional element of type Object Collection might be needed when it is difficult to predict pre-recognition results on different pages, but the search area can be accurately described, preventing unwanted information from getting into the hypotheses.
The following question may arise: why a regular expression is needed if the field can sometimes be detected without it? The answer is that the use of a regular expression makes the search more reliable. If this element is found, then you can be sure that you have found the very line that you need. This information can then be safely used to detect further elements and their relations. When the search constraints are lax, you cannot be absolutely sure that you have found exactly what you need.
This may happen if the image is very noisy. In such cases, the use of an element of type Character String with a specified alphabet can lead to the excessive percentage of errors (the Percentage of non-alphabet characters parameter). As a result, the element will be either not detected at all, or detected only partially. The example of such a situation is given in the picture below.
4/12/2024 6:16:02 PM