French (Français)
Onglet 2. Traitement de la boîte de dialogue Propriétés du workflow
L'onglet 2. Traitement contient les options de reconnaissance.
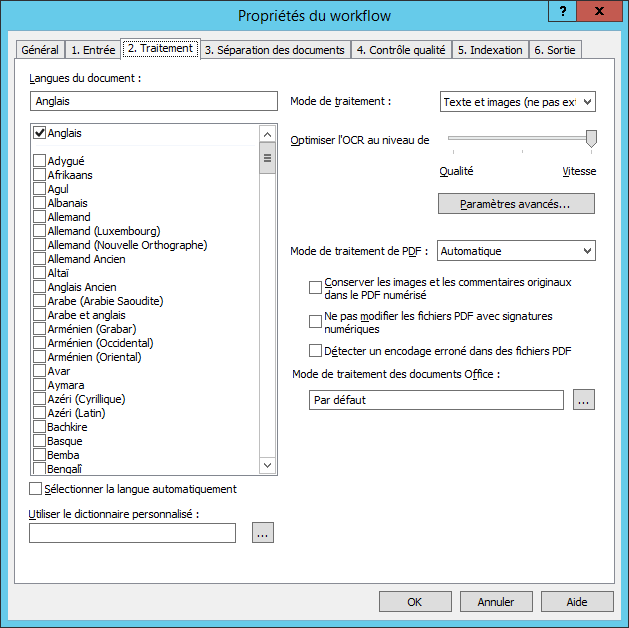
| Nom de l'option | Description de l'option |
| Langues du document | Spécifie les langues de reconnaissance. Les langues sont triées par ordre alphabétique et sont réparties en deux groupes. Le premier contient les langues avec dictionnaire, le deuxième contient les langues sans dictionnaire. Consultez la section Liste des langues de reconnaissance. |
| Sélectionner la langue automatiquement |
Si vous utilisez des langues sélectionnées dans la liste Langues du document, la langue du document sera automatiquement détectée.
|
| Optimiser l'OCR au niveau de | Permet d'optimiser la reconnaissance en fonction de la vitesse ou de la qualité. |
| Utiliser le dictionnaire personnalisé | Spécifie le chemin d'accès à un dictionnaire personnalisé qui sera utilisé lors de la reconnaissance. Un dictionnaire personnalisé est un fichier texte au format de codage UTF-16, où les mots sont représentés sous forme de liste, chaque ligne contenant un mot. |
| Mode de traitement |
Spécifie le mode de reconnaissance :
|
|
Paramètres avancés... (bouton) |
Ouvre la boîte de dialogue Paramètres de traitement avancés. |
| Mode de traitement de PDF |
|
| Conserver les images et les commentaires originaux dans le PDF numérisé |
La couche d'image, les notes et les commentaires d'origine seront conservés dans les fichiers de sortie.
|
| Ne pas modifier les fichiers PDF avec signatures numériques | Le texte des documents PDF sera soumis à l'OCR, mais les documents originaux resteront intacts et leurs signatures numériques seront préservées. |
| Mode de traitement des documents Office | Dans la liste déroulante, vous pouvez sélectionner une application Microsoft Office ou LibreOffice à utiliser pour le traitement des documents Office (c.-à-d., les fichiers *.doc, *.docx, *.odt, *.html, *.htm, *.txt, *.rtf; *.xls, *.xlsx, *.ods; *.ppt, *.pptx et *.odp). |
 Note. La sélection de cette option peut ralentir ABBYY FineReader Server lors du traitement de textes dans des langues autres qu'européennes.
Note. La sélection de cette option peut ralentir ABBYY FineReader Server lors du traitement de textes dans des langues autres qu'européennes.Voir également
3/26/2024 1:49:50 PM