German (Deutsch)
Registerkarte "2. Verarbeitung" des Dialogfelds "Workflow-Eigenschaften"
Die Registerkarte 2. Verarbeitung umfasst verschiedene Erkennungsoptionen.
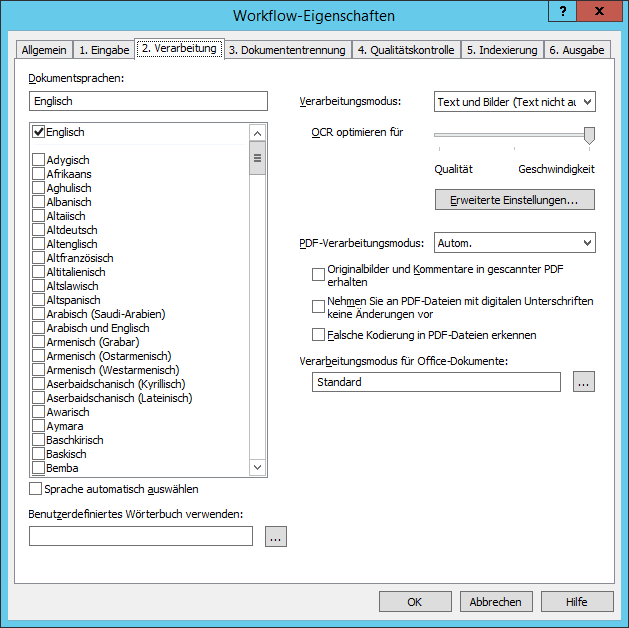
| Name der Option | Beschreibung der Option |
| Dokumentsprachen | Gibt die Erkennungssprachen an. Die Sprachen sind alphabetisch sortiert und in zwei Gruppen aufgeteilt: Die erste Gruppe enthält Sprachen mit vollständiger Wörterbuchunterstützung, die zweite Gruppe enthält Sprachen ohne Wörterbuchunterstützung. Siehe Liste der Erkennungssprachen. |
| Sprache automatisch auswählen |
Die Dokumentsprache wird automatisch anhand der in der Liste Dokumentsprachen ausgewählten Sprachen erkannt.
|
| OCR optimieren für | Gibt den Modus an, mit dem die Erkennung nach Qualität oder Geschwindigkeit optimiert wird. |
| Benutzerdefiniertes Wörterbuch verwenden | Gibt den Pfad eines benutzerdefinierten Wörterbuchs an, das bei der Erkennung verwendet werden soll. Ein benutzerdefiniertes Wörterbuch ist eine Textdatei in UTF-16-Kodierung, in der die Wörter als Liste mit einem Wort pro Zeile enthalten sind. |
| Verarbeitungsmodus |
Gibt den Erkennungsmodus an:
|
|
Erweiterte Einstellungen... (Schaltfläche) |
Öffnet das Dialogfeld Erweiterte Verarbeitungseinstellungen. |
| PDF-Verarbeitungsmodus |
|
| Originalbilder und Kommentare in gescannter PDF erhalten |
Die originale Bildebene, Notizen und Kommentare werden in den Ausgabedateien beibehalten.
|
| Nehmen Sie an PDF-Dateien mit digitalen Unterschriften keine Änderungen vor | Der Text in PDF-Dokumenten wird einem OCR unterzogen, aber die Originaldokumente bleiben intakt und deren digitalen Signaturen werden beibehalten. |
| Verarbeitungsmodus für Office-Dokumente | Sie können in der Dropdownliste eine Microsoft Office- oder LibreOffice-Anwendung für die Verarbeitung von Office-Dokumenten auswählen (z. B. Dateien des Typs *.doc, *.docx, *.odt, *.html, *.htm, *.txt, *.rtf; *.xls, *.xlsx, *.ods; *.ppt, *.pptx, und *.odp). |
 Hinweis. Die Auswahl dieser Option kann ABBYY FineReader Server bei der Verarbeitung von Texten in nicht-europäischen Sprachen verlangsamen.
Hinweis. Die Auswahl dieser Option kann ABBYY FineReader Server bei der Verarbeitung von Texten in nicht-europäischen Sprachen verlangsamen.Weitere Informationen
26.03.2024 13:49:48