Japanese (日本語)
[2. プロセス]ワークフロープロパティのダイアログボックスのタブ
2. プロセスタブには、認識オプションが含まれています。
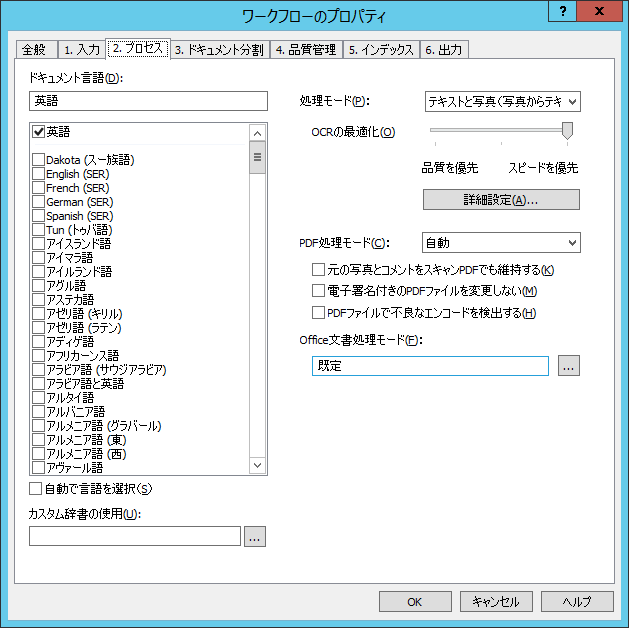
| オプション名 | オプションの説明 |
| ドキュメント言語 | 認識言語を指定します。言語はアルファベット順にソートされ、二つのグループに分けられます:一つのグループは辞書サポート付きの言語であり、もう一つのグループは辞書サポート無しの言語です。認識言語のリストを参照してください。 |
| 自動で言語を選択 |
ドキュメントの言語は ドキュメント言語リスト で選択した言語を使って自動的に検出されます。
|
| OCRの最適化 | 認識の品質、または速度を最適化するためのモードを指定します。 |
| カスタム辞書の使用 | 認識中に使用されるカスタム辞書へのパスを指定します。カスタム辞書は UTF-16 符号化形式のテキストファイルであり、単語はすべてリストとして表され、各行には一つの単語が含まれています。 |
| 処理モード |
認識モードを指定します:
|
|
詳細設定... (ボタン) |
高度な処理設定ダイアログボックスを開きます。 |
| PDF処理モード |
|
| 元の写真とコメントをスキャンPDFでも維持する |
元の画像レイヤー、メモ、コメントは出力ファイルに保存されます。
|
| 電子署名付きのPDFファイルを変更しない | PDF ドキュメントのテキストは OCR の対象となりますが、元のドキュメントはそのまま残り、デジタル署名は保持されます。 |
| Office文書処理モード | ドロップダウンリストから、Office ドキュメントの処理で使用する Microsoft Office または LibreOffice アプリケーションを選択します (例: *.doc, *.docx, *.odt, *.html, *.htm, *.txt, *.rtf; *.xls, *.xlsx, *.ods; *.ppt, *.pptx, *.odp ファイル)。 |
 注:このオプションを選択すると、非ヨーロッパ言語のテキストを処理する際にABBYY FineReaderサーバーが遅くなる可能性があります。
注:このオプションを選択すると、非ヨーロッパ言語のテキストを処理する際にABBYY FineReaderサーバーが遅くなる可能性があります。こちらも参照してください:
26.03.2024 13:49:51