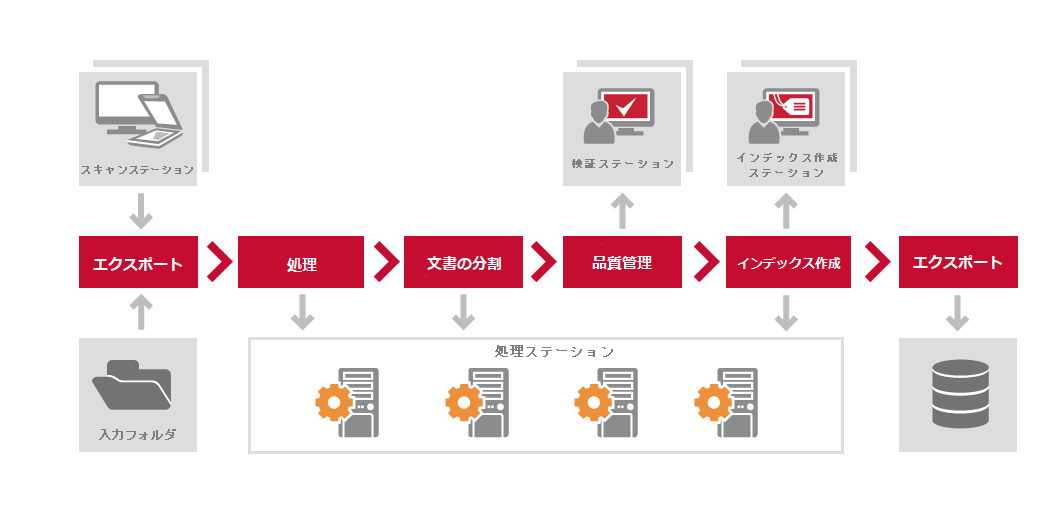
文書のワークフロー
ABBYY FineReader Server 14 への画像の送信からエクスポートの終了までには、以下の処理手順が実行されます。
スキャニング/インポート
このステージでは、画像はスキャンステーションでスキャンされるか、ABBYY FineReader Serverによりホットフォルダまたはメールボックスからインポートされるか、 ABBYY FineReader Server 14 ドキュメント変換サービスを使用してインポートされます。 注:デフォルトでは、画像ファイルは名前で並べ替えられ、辞書順にServer Managerに送信されます(例えば、file10.jpgはfile2.jpgの前に来ます)。これはサーバー設定で変更できます。詳しくは、「ダイアログボックス:FineReaderサーバーのプロパティ」を参照してください 。
注:デフォルトでは、画像ファイルは名前で並べ替えられ、辞書順にServer Managerに送信されます(例えば、file10.jpgはfile2.jpgの前に来ます)。これはサーバー設定で変更できます。詳しくは、「ダイアログボックス:FineReaderサーバーのプロパティ」を参照してください 。
画像ファイルがスキャニングステーション、入力フォルダまたはメールボックスから Server Manager に送信されると、Server Manager はそれらの処理のためにジョブおよびキューを作成します。 複数のワークフローがセットアップされている場合には、ABBYY FineReader Server は 1 つのキュー内で、すべてのワークフローからのジョブを処理します。 ジョブは作成時間と優先度に従って調整されます。
注:Server Manager はABBYY FineReader Server 14 一時フォルダの画像サブフォルダにすべての画像ファイルを保存します。 Server Manager 一時フォルダはリモート管理コンソールのFineReader Server プロパティダイアログボックスで表示および変更が可能です。 画像ファイルは変換プロセス全般を通じてそのフォルダに保存されます。 処理ステーション、検証ステーション、インデックス作成ステーション はこれらの画像のコピーを処理のために受信します。 これにより、認識、確認、インデックス作成の途中でエラーが発生した場合でも、ファイルは紛失しないようにします、
スキャニングのコツ
変換品質は、元の文書の品質とスキャン パラメータにより左右されます。 画像品質が低いと、変換の品質が悪くなる可能性があります。 必ず文書に適したスキャン パラメータを選択してください。
300 dpi での文書のスキャンを推奨します。
 重要事項!縦、横の解像度は同じでなければなりません。
重要事項!縦、横の解像度は同じでなければなりません。
設定した解像度が高すぎると (600 dpi 以上) 、認識時間が長くなります。
解像度を高めても、認識結果が大幅に向上することはありません。 非常に低い解像度 (150 dpi 未満) を設定すると、OCR 品質が低下します。
フォントサイズによって解像度を選択するための推奨事項:
- 通常のテキスト (10 pt 以上のフォント サイズで印刷されているテキスト) には 300 dpi
- それ以下(9pt またはそれ以下)のフォントで印刷されたテキストおよびバーコードを含む画像の場合、400-600 dpi。
処理
キューの最初のジョブは認識のために最初の利用可能な 処理ステーション に送られます。 複数の 処理ステーション がシステムに存在する場合、Server Manager はキューから複数の 処理ステーション 間に均等にジョブを分配します。 新しい 処理ステーション の登録を参照してください。
処理ステーション は複数の OCR プロセスを実行することができます(その数はリモート管理コンソールで調整できます)。 最適なパフォーマンスのために、1 つのステーションへのプロセスの数として推奨されるのは、ステーションの CPU コアの数を N とした場合に N+1 です 各 OCR プロセスは一度に 1 つのファイルを受け取ります。 例えば、処理ステーション が 2 つの OCR プロセスを実行する場合、2 つのファイルを平行して認識します(同一ジョブから、または別々のジョブから)。 しかし、ファイルが多くのページから成るもの(例: 数十枚)で、大きなファイルは複数の小さなグループに分けられ、それぞれのグループは迅速に作業を終えるために、別の OCR プロセスに送られます。
処理ステーション がファイルの処理を終えたら、認識されたファイルを Server Manager に戻し、キューから次のジョブが割り当てられます。
文書の分割
認識後、ジョブキューのページは、分割ルールに従って文書に再度アレンジされます。 文書の分割はジョブ内で実行されます。 インポートステージで指定されたソースにより、別の文書分割方法が利用できます。 ビルトインの文書分割方法(バーコード、空白のページなどによる方法)に加えて、スクリプトを使った分割を実行することもできます。 文書の分割の設定を参照してください。
品質管理
確認がワークフロー設定で有効になっている場合、確認が必要な文書は組み立て後に確認のためにキューに入れられます。 検証ステーション が接続されている場合、Server Manager はキューに入れられた文書をそれらのステーションにルートします。 接続された 検証ステーション がない場合やステーションにログインしているユーザーがこのワークフローでの文書の確認を許可されていない場合、「確認のためにキュー」の状態でキューに残ります。 それらのファイルは確認が実行されるまで、次のプロセスのために先に送られることはありません。 確認の設定を参照してください。
インデックス作成
文書のタイプおよび属性はワークフロー設定で定義されている場合、このワークフローで組み立てられた文書はインデックス作成のためにキューに入れられます。 インデックス作成は インデックス作成ステーション でスクリプトの支援を受けて自動で、および/または手動で行うことができます。 まず、スクリプトが定義されている場合、インデックス作成はスクリプトに従って実行されます。 その後、手動のインデックス作成が必要な文書またはインデックスの確認が必要な文書は インデックス作成ステーション のキューに入れられます。 インデックス作成ステーション が接続されている場合、Server Manager はキューに入れられた文書をそれらのステーションに送ります。 インデックス作成ステーション が現在接続されていない場合またはステーションにログオンしているユーザーがこのワークフローで文書にインデックス作成を許可されていない場合、文書は「インデックス作成のためにキュー」の状態でキューに残ります。 文書のインデックス作成設定を参照してください。
エクスポート
認識、確認、インデックス作成が完了したら、出力文書は、Server Manager に戻され、発行のためにキューに入れられます。 サーバーマネージャーは、出力ドキュメントをジョブ設定で指定された宛先に配信するか、ABBYY FineReader Server 14ドキュメント変換サービスを使用している場合には、ユーザーが選択した場所に保存するオプションを提供します。 出力ファイルは出力フォルダに発行後、画像のコピーは Server Manager 一時フォルダから削除されます。
エクスポートの処理スクリプトが発行されたジョブのために定義されている場合、出力文書および XML 結果ファイルが出力フォルダに発行された時、トリガーされます。 エクスポート処理スクリプトは出力文書を文書のタイプ、属性、認識統計などにより、適切な宛先に届けるために使用することができます。
失敗したジョブのためのスクリプトは処理に失敗し、例外フォルダに入れられた画像の処理のために定義することができます。
こちらも参照してください:
3/26/2024 1:49:51 PM