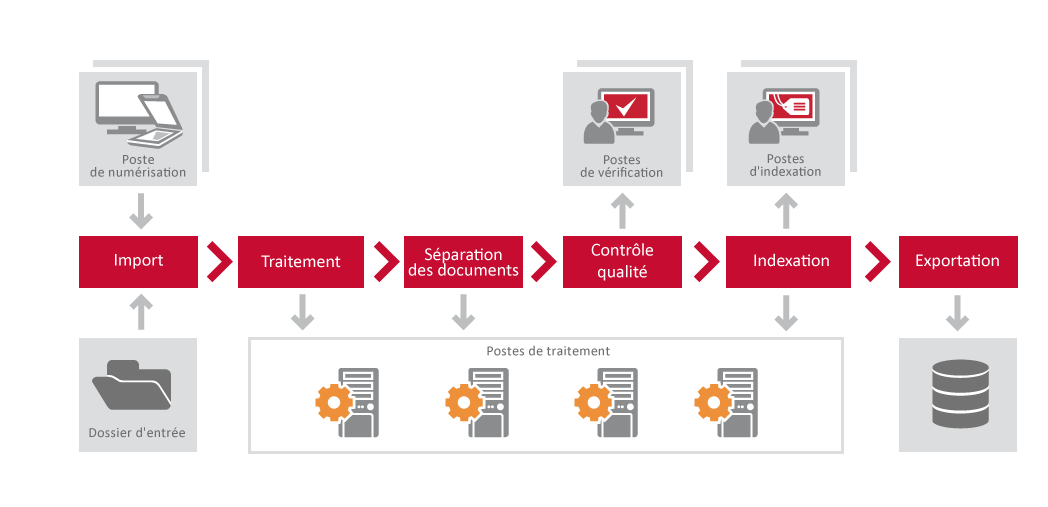
Workflow de document
Les étapes de traitement suivantes s'effectuent en commençant par la soumission d'une image à ABBYY FineReader Server 14 et finissant par l'exportation :
- Numérisation/importation
- Reconnaissance
- Séparation de document
- Vérification(optionnel)
- Indexation(optionnel)
- Exportation
Numérisation/importation
À ce stade, les images sont soit numérisées sur le poste de numérisation soit importées par ABBYY FineReader Server depuis un dossier d'images ou une messagerie ou à l'aide du service de conversion de documents d'ABBYY FineReader Server 14. Note. Par défaut, les fichiers image sont triés par nom et sont envoyés au Gestionnaire de serveur dans l'ordre lexicographique (par exemple, file10.jpg viendra avant file2.jpg). Cela peut être modifié dans les paramètres du serveur. Pour plus d'informations, veuillez consulter la boîte de dialogue : Propriétés du serveur FineReader.
Note. Par défaut, les fichiers image sont triés par nom et sont envoyés au Gestionnaire de serveur dans l'ordre lexicographique (par exemple, file10.jpg viendra avant file2.jpg). Cela peut être modifié dans les paramètres du serveur. Pour plus d'informations, veuillez consulter la boîte de dialogue : Propriétés du serveur FineReader.
Une fois les fichiers d'images soumis au Gestionnaire de serveur à partir du poste de vérification, du dossier Entrée ou de la boîte de réception, le Gestionnaire de serveur crée des tâches pour ceux-ci et les met dans la file de traitement. Si plusieurs workflows sont configurés, ABBYY FineReader Server traite simultanément les tâches de tous ces workflows, au sein de la même file. Les tâches sont classées dans la file en fonction de leur date de création et de leur niveau de priorité.
Note. Les Gestionnaire de serveur stocke tous les fichiers d'images dans le sous-dossier Images du dossier temporaire d'ABBYY FineReader Server 14. Le chemin d'accès du dossier temporaire du Gestionnaire de serveur peut être affiché et modifié dans le boîte de dialogue Propriétés de FineReader Server Propriétés du serveur de reconnaissance de la Console d'administration à distance. Les fichiers d'images sont conservés dans ce dossier pendant toute la durée du processus de conversion. Les Postes de traitement, Postes de vérification, et Postes d'indexation reçoivent des copies de ces images pour leur traitement. Cela permet d’éviter la perte de fichiers en cas d’erreur lors de la reconnaissance, de la vérification ou de l'indexation.
Conseils pour la numérisation
La qualité de la conversion dépend de la qualité du document d'origine et des paramètres de numérisation. Une image de mauvaise qualité peut nuire à la qualité de la conversion. Veillez sélectionner les paramètres de numérisation adaptés à votre document.
Nous vous recommandons de numériser vos documents avec une résolution de 300 ppp.
 Important! Les résolutions horizontale et verticale doivent être identiques.
Important! Les résolutions horizontale et verticale doivent être identiques.
La durée nécessaire à la reconnaissance augmente si vous choisissez une résolution trop élevée (plus de 600 ppp). Une résolution plus élevée ne produit pas d'amélioration substantielle sur les résultats de la reconnaissance. Une résolution extrêmement basse (moins de 150 ppp) nuit à la qualité de la reconnaissance.
Recommandations pour le choix de la résolution en fonction de la taille de la police :
- 300 ppp : pour le texte normal (imprimé dans des polices de taille 10 ou plus)
- 400 à 600 ppp : pour le texte imprimé dans des polices plus petites (de taille 9 ou moins) et les images contenant des codes-barres.
Reconnaissance
La première tâche de la file est envoyée au premier poste de traitement disponible pour effectuer sa reconnaissance. Si le système comporte plusieurs postes de traitement, le Gestionnaire de serveur répartit équitablement les tâches de la file entre ces différentes stations. Consultez la section Comment enregistrer un nouveau poste de traitement.
Un poste de traitement peut exécuter plusieurs processus d’OCR (leur nombre pouvant être défini dans la console de gestion à distance). Pour une performance optimale, le nombre de processus recommandés pour un poste s’élève à N+1, N étant le nombre de cœurs de processeur du poste. Généralement, chaque processus d’OCR reçoit un fichier à la fois. Par exemple, si un poste de traitement exécute deux processus d’OCR, elle reconnaît les deux fichiers en parallèle (qu’ils appartiennent à la même tâche ou à deux tâches distinctes). Toutefois, si le fichier comporte un grand nombre de pages (plusieurs dizaines), il est divisé en plusieurs parties qui sont alors envoyées à différents processus d’OCR afin d’accélérer le travail.
Lorsque le poste de traitement a terminé le fichier, elle renvoie le fichier reconnu au serveur gestionnaire et commence à traiter la tâche suivante dans la liste.
Séparation des documents
Après la reconnaissance, les pages contenues dans la file d'attente de tâches seront réorganisées en documents conformément à la règle de division. La séparation de documents s'effectue dans le cadre d'une tâche. Différentes méthodes de séparation de documents sont disponibles en fonction de la source spécifiée dans l'étape d'importation. En plus des méthodes de séparation de documents intégrées (par codes-barres, pages vides, etc.), il est également possible d'effectuer la séparation à l'aide d'un script. Consultez la section Configuration de la séparation des documents.
Vérification
Si la vérification est activée dans les paramètres de workflows, les documents devant être vérifiés seront mis en attente de vérification une fois l'assemblage achevé. Si des postes de vérification sont connectées, le gestionnaire de serveur achemine les documents de la file vers ces postes. Si aucun poste de vérification n’est actuellement connecté ou si les utilisateurs connectés à ces postes n’ont pas l’autorisation permettant de vérifier les documents de ce workflow, ceux-ci restent dans la file, dans l’état "En attente de vérification". Elles ne seront pas acheminées pour la suite du traitement avant d'avoir été vérifiées. Consultez la section Comment configurer la vérification.
Indexation
Si les types et attributs de documents sont définis dans les paramètres du workflow, les documents assemblés à partir de ce workflow seront placés dans la file d'indexation. L'indexation peut s'effectuer par le biais d'un script et/ou manuellement sur un poste d'indexation. Tout d'abord, si un script est défini, l'indexation s'effectue selon ce script. Ensuite, les documents qui nécessitent une indexation manuelle ou une vérification d'index sont placés dans la file des postes d'indexation. Si des postes d'indexation sont connectées, le Gestionnaire de serveur achemine les documents de la file vers ces postes. Si aucun poste de vérification n’est actuellement connecté ou si les utilisateurs connectés à ces postes n’ont pas l’autorisation d'indexer les documents de ce workflow, ceux-ci restent dans la file, dans l’état «En attente d'indexation». Consultez la section Comment configurer l'indexation des documents.
Exportation
Lorsque la reconnaissance, la vérification et l'indexation sont terminées, les fichiers de sortie sont renvoyés au Gestionnaire de serveur et placés dans la file de publication. Le Gestionnaire de serveurs transmet les documents de sortie à la destination spécifiée dans les paramètres de la tâche ou vous donne la possibilité de les enregistrer à l'emplacement de votre choix si vous utilisez le service de conversion de documents d'ABBYY FineReader Server 14. Une fois que le fichier a été transféré dans le dossier Sortie, la copie de l’image est supprimée du dossier temporaire du Gestionnaire de serveur.
Si le script responsable de l'exportation est défini pour les tâches dont la publication a réussi, il se déclenchera lorsque les documents de sortie et le fichier de résultats XML seront transférés dans le dossier Sortie. Le script responsable de l'exportation peut être utilisé pour envoyer les documents de sortie vers une destination adéquate, selon le type de document, les attributs du document, les statistiques sur la reconnaissance, etc.
Un script pour les tâches ayant échoué peut être défini pour prendre en charge les images dont le traitement a échoué et qui ont été placées dans le dossier Exceptions.
Voir également
3/26/2024 1:49:50 PM