Spanish (Español)
Ficha 2. Proceso del cuadro de diálogo Propiedades del flujo de trabajo
La ficha 2. Proceso incluye opciones de reconocimiento.
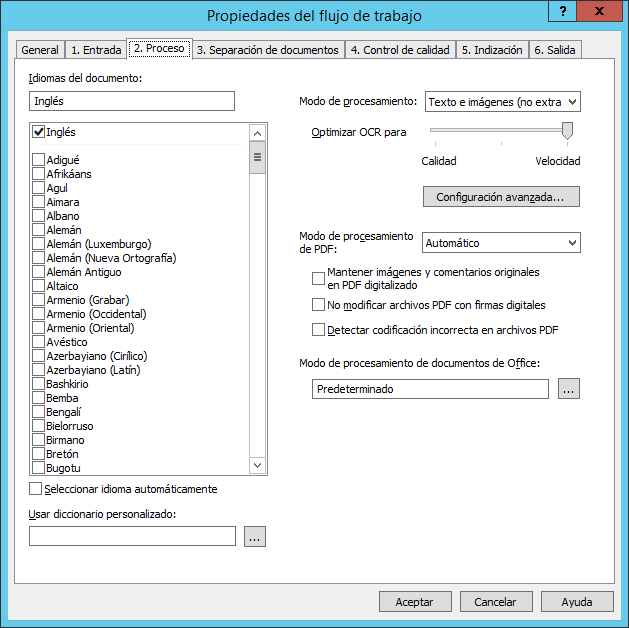
| Nombre de la opción | Descripción de la opción |
| Idiomas del documento | Especifica los idiomas de reconocimiento. Los idiomas se ordenan alfabéticamente y se dividen en dos grupos: el primero incluye idiomas con acceso total al diccionario, el segundo grupo incluye idiomas sin acceso al diccionario. Consulte Lista de idiomas de reconocimiento. |
| Seleccionar idioma automáticamente |
El idioma del documento se detectará automáticamente usando los idiomas seleccionados en la lista Idiomas del documento.
|
| Optimizar OCR para | Especifica el modo que optimiza el reconocimiento de calidad o velocidad. |
| Usar diccionario personalizado | Especifica la ruta de un diccionario personalizado que se utilizará durante el reconocimiento. Un diccionario personalizado es un archivo de texto con codificación UTF-16 donde las palabras se representan en forma de lista en la que cada línea contiene una palabra. |
| Modo de procesamiento |
Especifica el modo de reconocimiento:
|
|
Configuración avanzada... (botón) |
Abre el cuadro de diálogo Configuración avanzada de procesamiento. |
| Modo de procesamiento de PDF |
|
| Mantener imágenes y comentarios originales en PDF digitalizado |
En los archivos de salida se conservarán la capa de imagen, las notas y los comentarios originales.
|
| No modificar archivos PDF con firmas digitales | El texto de los documentos PDF se someterá a OCR, pero los documentos originales no sufrirán cambios (también se conservará su firma digital). |
| Modo de procesamiento de documentos de Office | En la lista desplegable, puede seleccionar la aplicación de Microsoft Office o LibreOffice que se utilizará para procesar documentos de Office (esto es, archivos *.doc, *.docx, *.odt, *.html, *.htm, *.txt, *.rtf, *.xls, *.xlsx, *.ods, *.ppt, *.pptx y *.odp). |
 Nota. Si selecciona esta opción, es posible que ABBYY FineReader Server se ralentice al procesar textos en idiomas no europeos.
Nota. Si selecciona esta opción, es posible que ABBYY FineReader Server se ralentice al procesar textos en idiomas no europeos.Consulte también:
26.03.2024 13:49:49