2. ProcessDialog Box: Workflow Properties, Tab: Process
The 2. Process tab contains recognition options.
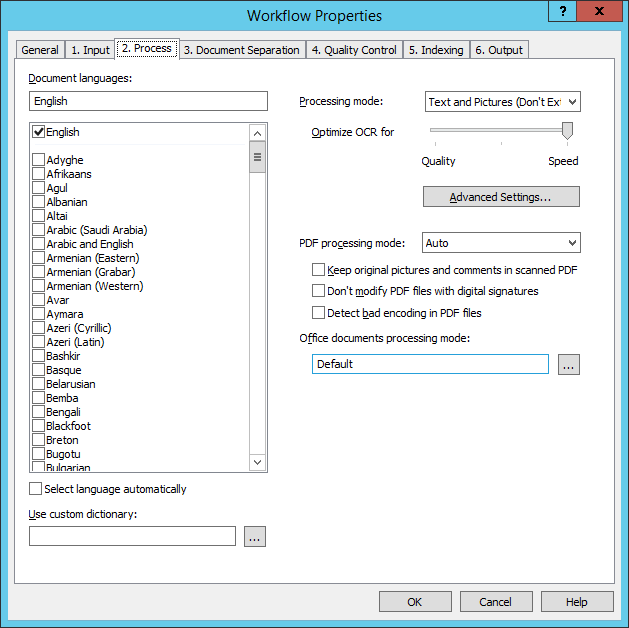
| Option name | Option description |
| Document languages | Specifies recognition languages. Languages are sorted alphabetically and are divided into two groups: the first group includes languages with full dictionary support, while the second group includes languages without dictionary support. For more information, see List of Recognition Languages. |
| Select language automatically |
The document language will be detected automatically using the languages selected in the Document languages list.
|
| Optimize OCR for | Specifies whether recognition should be optimized for quality or for speed. |
| Use custom dictionary | Specifies the path to the custom dictionary that should be used during recognition. A custom dictionary is a UTF-16 text file where each line of text represents a separate word. |
| Processing mode |
Specifies the recognition mode:
|
|
Advanced Settings... (button) |
Opens the Advanced Processing Settings dialog box. |
| PDF processing mode |
|
| Keep original pictures and comments in scanned PDF |
The original image layer, notes, and comments will be preserved in the output files.
|
| Don't modify PDF files with digital signatures | The text areas in PDF documents will be subjected to OCR, but the original documents will remain intact and their digital signatures will be preserved. |
| Detect bad encoding in PDF files |
If an input PDF document has a text layer, the program will check its encoding. If bad encoding is detected, the program will perform OCR on the document.
|
| Office documents processing mode | From the drop-down list, you can select a Microsoft Office or LibreOffice application to be used for processing Office documents (i.e. *.doc, *.docx, *.odt, *.html, *.htm, *.txt, *.rtf; *.xls, *.xlsx, *.ods; *.ppt, *.pptx, and *.odp files). |
 Note. Selecting this option may slow down ABBYY FineReader Server when processing texts in non-European languages.
Note. Selecting this option may slow down ABBYY FineReader Server when processing texts in non-European languages.See also
26.03.2024 13:49:49