Tab: Settings
Thorough analysis
In ABBYY FineReader Server 14, Fast analysis of document metadata is enabled by default. Page count information obtained using this analysis type will only be an approximation:
- For some files, the number of pages they contain cannot be calculated.
For example, table files (XLS, XLSX, and ODS) are not divided into pages. - During processing, the number of pages may increase for input files that contain pages larger than A4.
- A PDF file with a good text layer that contains pages with no text may require re-recognition.
See also: Rules for deducting pages for jobs.
In order to get more a more precise page count, navigate to the Settings tab in the Audit workflow settings dialog box and select Thorough analysis. This analysis type is available in FineReader Server 14 R3 Update 2 and later versions.
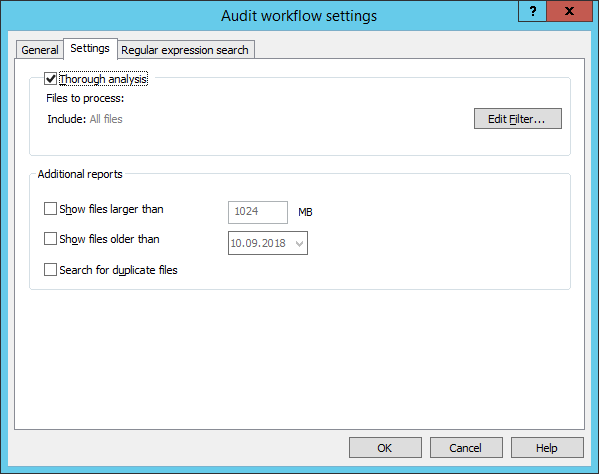
Thorough analysis uses ABBYY's optical character recognition technology to analyze documents, which helps calculate the number of pages that will be required for processing with maximum precision.
 Note. Thorough analysis significantly slows down document processing.
Note. Thorough analysis significantly slows down document processing.
You can set up an input file filter for thorough analysis and regular expression searches. To do so, navigate to the Settings tab in the Audit workflow settings dialog and click Edit Filter... Using an input filter can decrease the number of documents processed, thereby improving analysis speed.
Note. The filter is not used when analyzing document metadata (enabled by default) and when creating additional reports.
Additional reports
In the audit workflow settings, you can specify additional reports to be created for specific file categories:
- Files that are over the specified size limit (in megabytes).
Processing large files is not always desirable, as it can slow down your system and delay other tasks. This report can be used to decide which large files to process separately. - Files that were last modified before the specified date.
This report lets you determine the percentage of outdated files whose processing can be delayed. - Duplicate files.
This report contains a list of all duplicate files found in the storage, as well as their sizes and locations. This will let you optimize your storage and process only the files that you actually require processing.
Note. Enabling duplicate search can significantly slow down the audit workflow.
Note. If there are custom columns in your SharePoint library, duplicate search will not work for DOC, DOCX, XLS, XLSX, PPT, and PPTX documents, as Microsoft SharePoint will modify these types of files by adding custom properties.
26.03.2024 13:49:49