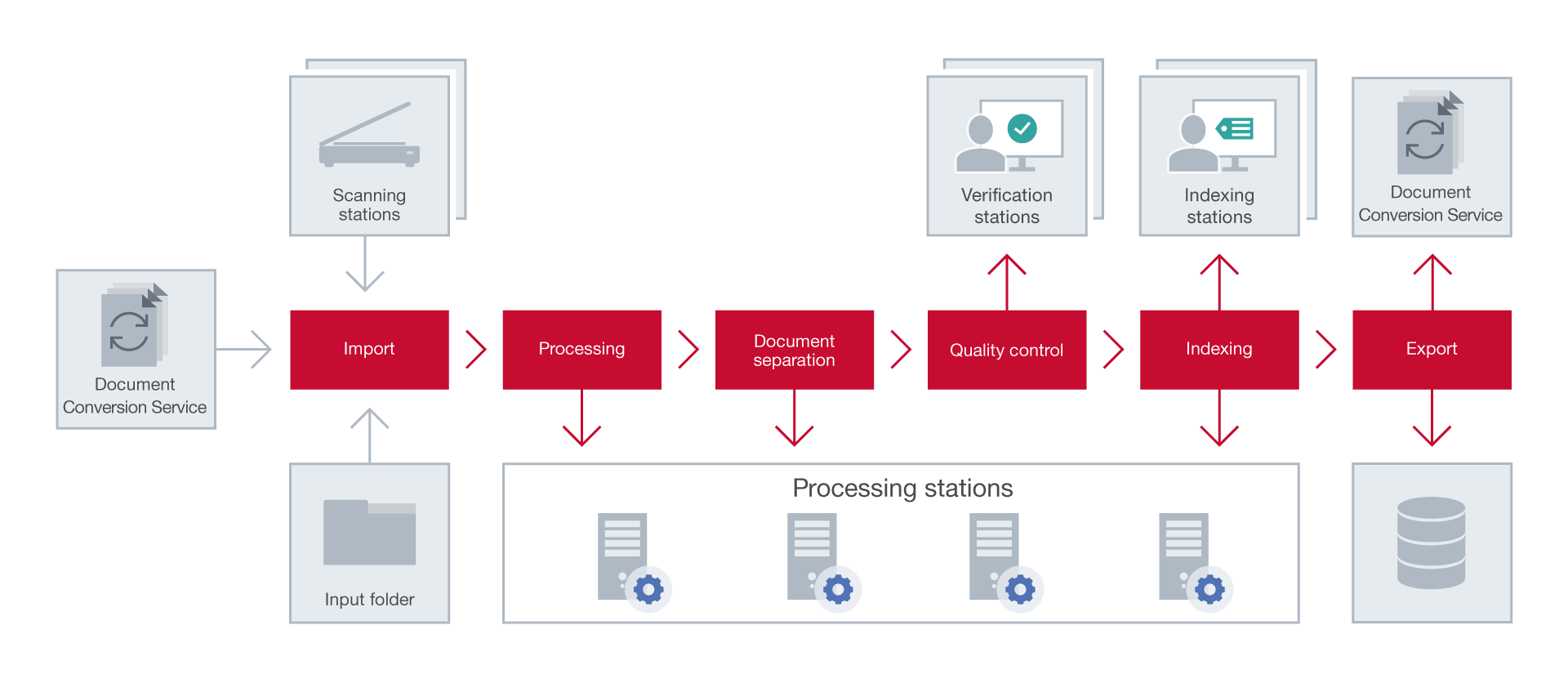
Document Workflow
The following processing steps are performed, starting from image submission to ABBYY FineReader Server 14 and ending with export:
- Scanning/import
- Processing
- Document separation
- Quality control (optional)
- Indexing (optional)
- Export
Scanning/import
At this stage, images are either scanned on the Scanning Station or imported by ABBYY FineReader Server from a hot folder or a mailbox, or using the ABBYY FineReader Server 14 Document Conversion Service. Note. By default, image files are sorted by name and are sent to the Server Manager in lexicographical order (e.g. file10.jpg will come before file2.jpg). This can be changed in the server settings. For more information, please see Dialog Box: FineReader Server Properties.
Note. By default, image files are sorted by name and are sent to the Server Manager in lexicographical order (e.g. file10.jpg will come before file2.jpg). This can be changed in the server settings. For more information, please see Dialog Box: FineReader Server Properties.
Once image files are submitted to the Server Manager from the Scanning Station, Input folder or mailbox, the Server Manager creates jobs for them and queues them for processing. If several workflows are set up, ABBYY FineReader Server will process jobs from all workflows simultaneously, within a single queue. The jobs will be arranged in the queue according to their creation time and priority.
Note. The Server Manager stores all image files in the Images subfolder of the ABBYY FineReader Server 14 temporary folder. The path to the Server Manager temporary folder can be viewed and changed in the FineReader Server Properties dialog box of the Remote Administration Console. The image files are kept in that folder throughout the entire conversion process. The Processing Stations, Verification Stations, and Indexing Stations receive copies of those images for processing. This ensures that no files are lost in case an error occurs during recognition, verification, or indexing.
Scanning tips
Conversion quality depends on the quality of the original document and scanning parameters. Poor image quality may have an adverse effect on the quality of conversion. Be sure to select the scanning parameters appropriate for your document.
We recommend scanning documents at 300 dpi.
 Important! Vertical and horizontal resolutions must be the same.
Important! Vertical and horizontal resolutions must be the same.
Setting the resolution too high (over 600 dpi) increases the recognition time. Increasing the resolution does not yield substantially improved recognition results. FineReader Server supports resolutions up to 3200 dpi. Greater resolutions will be lowered automatically.
Setting an extremely low resolution (less than 150 dpi) adversely affects recognition quality.
Recommendations for choosing the resolution depending on the font size:
- 300 dpi — for typical texts (printed in fonts of size 10 pt or larger)
- 400—600 dpi — for texts printed in smaller fonts (9 pt or smaller) and images with barcodes.
Processing
The first job in the queue is sent to the first available Processing Station for recognition. If there are several Processing Stations in the system, the Server Manager evenly distributes the jobs from the queue among these Processing Stations. See Registering a New Processing Station.
A Processing Station can run several OCR processes (their number can be adjusted in the Remote Administration Console). For optimal performance, the recommended number of processes for a station is N+1, where N is the number of CPU cores on the station. Usually each OCR process gets one file at a time. For example, if a Processing Station runs two OCR processes, it will recognize two files in parallel (they can belong to the same job or different jobs). However, if the file has many pages (e.g. several dozen), the big file will be split into several chunks, and the chunks will be sent to different OCR processes in order to complete the work faster. In addition to this, you should keep in mind that processing a large number of files in one job will degrade performance, so it's a good idea to place as few files in jobs as possible.
When the Processing Station has finished processing the file, it returns the recognized file to the Server Manager and is assigned the next job from the queue.
Document separation
After recognition, the pages in the job queue will be rearranged into documents according to the separation rule. Document separation is performed within a job. Depending on the source specified in the Import stage, different document separation methods are available. In addition to built-in document separation methods (by barcodes, blank pages, etc.) separation using a script can be performed. See Configuring Document Separation.
Quality control
If verification is turned on in the workflow settings, documents that require verification will be queued for verification after assembly. If Verification Stations are connected, the Server Manager will route the queued documents to those stations. If no Verification Stations are currently connected, or the users logged on the stations are not permitted to verify documents from this workflow, the documents will remain in the queue in "Queued for verification" state. They will not be forwarded for further processing until verified. See Configuring Verification.
Indexing
If document types and attributes are defined in the workflow settings, assembled documents from this workflow will be queued for indexing. Indexing can be performed automatically with the help of a script and/or manually at an Indexing Station. First, if a script is defined, indexing is carried out according to the script. Then, documents that require manual indexing or index verification are queued to the Indexing Stations. If Indexing Stations are connected, the Server Manager will forward the queued documents to those stations. If no Indexing Stations are currently connected, or the users logged on the stations are not permitted to index documents from this workflow, the documents will remain in the queue in "Queued for indexing" state. See Configuring Document Indexing.
Export
When recognition, verification, and indexing are complete, the output documents are handed back to the Server Manager and queued for publishing. The Server Manager delivers the output documents to the destination specified in the job settings, or gives you the option to save them to a location of your choice if you are using the ABBYY FineReader Server 14 Document Conversion Service. After the output files are published in the Output folder, the image copy is removed from the Server Manager temporary folder.
If the export handling script is defined for successfully published jobs, it will be triggered when the output documents and XML Result file are published to the Output folder. The export handling script can be used to deliver the output documents to an appropriate destination depending on the document type, document attributes, recognition statistics, etc.
A script for failed jobs can be defined to handle images that failed to be processed and were put into the Exceptions folder.
See also
26.03.2024 13:49:49