- English (English)
- Bulgarian (Български)
- Chinese Simplified (简体中文)
- Chinese Traditional (繁體中文)
- Danish (Dansk)
- Dutch (Nederlands)
- Estonian (Eesti)
- French (Français)
- German (Deutsch)
- Greek (Ελληνικά)
- Hebrew (עִברִית)
- Hungarian (Magyar)
- Italian (Italiano)
- Japanese (日本語)
- Korean (한국어)
- Polish (Polski)
- Portuguese (Brazilian) (Português (Brasil))
- Slovak (Slovenský)
- Spanish (Español)
- Swedish (Svenska)
- Turkish (Türkçe)
- Ukrainian (Українська)
- Vietnamese (Tiếng Việt)
Vlastnosti dokumentů, které je nutno vzít v úvahu před rozpoznáváním OCR
Kvalita obrazů má významný dopad na kvalitu OCR. V této části se popisuje, se kterými faktory je nutno počítat před rozpoznáváním obrazů.
Aplikace ABBYY FineReader rozpoznává jednojazyčné i vícejazyčné dokumenty (např. napsané dvěma a více jazyky). V případě vícejazyčných dokumentů je třeba zadat několik jazyků OCR.
Chcete-li vybrat jazyk OCR, klikněte na tlačítko Možnosti > Jazyky a vyberte jednu z následujících možností:
- Automaticky vybrat jazyky OCR z následujícího seznamu
Aplikace ABBYY FineReader automaticky vybere vhodné jazyky z uživatelsky definovaného seznamu jazyků. Chcete-li seznam jazyků upravit: - Ujistěte se, že je zvolená možnost Automaticky vybrat jazyky OCR z následujícího seznamu.
- Klikněte na tlačítko Zadat....
- V dialogovém okně Jazyky zvolte požadované jazyky a klikněte na OK.
- V dialogovém okně Možnosti klikněte na OK.
- Zadat jazyky OCR ručně
Pokud požadovaný jazyk není v seznamu, vyberte tuto možnost.
V dialogovém okně níže zadejte jeden nebo více jazyků. Pokud určitou jazykovou kombinaci používáte často, můžete pro tyto jazyky vytvořit novou skupinu.
Pokud požadovaný jazyk není v seznamu, jedná se o některou z následujících situací:
- Není podporován v aplikaci ABBYY FineReader nebo
 Kompletní seznam jazyků rozpoznávání najdete v části Podporované jazyky, viz kapitolu. Podporované jazyky OCR.
Kompletní seznam jazyků rozpoznávání najdete v části Podporované jazyky, viz kapitolu. Podporované jazyky OCR. - Není podporován ve vaší verzi produktu. Kompletní seznam jazyků, které jsou ve vaší verzi produktu k dispozici, naleznete v dialogovém okně Licence (klikněte na Nápověda > O aplikaci > Licenční informace, aby se toto dialogové okno otevřelo).
Kromě použití vestavěných jazyků a jazykových skupin můžete vytvářet i vlastní jazyky a skupiny. Viz také: Pokud program nedokáže rozpoznat určité znaky.
Dokumenty lze tisknout na různých zařízeních, např. psacích strojích a faxech. Kvalita OCR se může lišit na základě toho, jak byl dokument vytištěn. Kvalitu rozpoznávání OCR můžete zlepšit tím, že vyberete správný typ tisku v dialogovém okně Možnosti.
U většiny dokumentů program zjistí typ tisku automaticky. Pro automatické zjištění typu tisku je nutno zvolit možnost Auto ve skupině možností Typ dokumentu v dialogovém okně Možnosti (klikněte na Nástroje > Možnosti... > OCR a získejte k těmto možnostem přístup). Dokumenty lze zpracovávat v plnobarevném nebo černobílém režimu.
Typ tisku můžete podle potřeby vybrat i ručně.
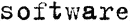 |
Příklad textu napsaného na psacím stroji. Všechna písmena mají stejnou šířku (porovnejte například „w“ a „t“). Pro texty tohoto typu zvolte Psací stroj. |
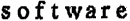 |
Příklad textu z faxového přístroje. Jak je z příkladu zřejmé, na určitých místech nejsou písmena zřetelná. Na obrazu je také jistý šum a jistá místa jsou zkreslená. Pro texty tohoto typu zvolte Fax. |
Po rozpoznávání strojopisných textů nebo faxů je nutno vybrat Auto a teprve poté zpracovat běžně tištěné dokumenty.
Dokumenty s nízkou kvalitou tisku neboli s „šumem“ (tj. náhodné černé tečky nebo skvrnky) nebo s rozmazanými a nestejnoměrnými písmeny, se šikmými řádky a posunutými okraji tabulek mohou vyžadovat specifické nastavení.
| Fax | Noviny |
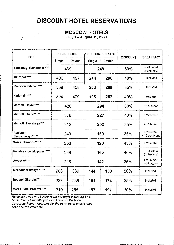 |
 |
Dokumenty nízké kvality je nejvhodnější skenovat ve stupních šedé. Při skenování ve stupních šedé program automaticky vybere optimální hodnotu jasu.
Režim skenování ve stupních šedé zachová ve skenovaném textu více informací o písmenech pro dosažení lepších výsledků OCR při rozpoznávání dokumentů střední nebo nízké kvality. Některé defekty tisku můžete také opravit s použitím nástrojů pro úpravu obrázků, dostupných v Editoru obrázků. Viz také: Má-li obraz dokumentu vady a přesnost OCR je nízká.
Pokud nepotřebujete zachovat původní barvy v plnobarevném dokumentu, můžete ho zpracovat v černobílém režimu. Značně se tím zmenší velikost výsledného dokumentu projektu OCR a urychlí se proces OCR. Nicméně zpracování obrazů s nízkým kontrastem v černobílém režimu může vést ke špatné kvalitě rozpoznávání. Černobílé zpracování také nedoporučujeme pro fotografie, stránky z časopisů a texty v čínštině, japonštině a korejštině.
Tip. OCR barevných a černobílých dokumentů můžete také zrychlit tím, že vyberete Rychlé rozpoznávání na kartě OCR dialogového okna Možnosti. Další informace o režimech rozpoznávání naleznete v kapitole Možnosti OCR.
Některá další doporučení ohledně výběru správného barevného režimu viz Tipy pro skenování.
 Po převodu dokumentu na černobílý již barvy nelze obnovit. Pro získání barevného dokumentu otevřete soubor s barevnými obrázky nebo papírový dokument naskenujte v barevném režimu.
Po převodu dokumentu na černobílý již barvy nelze obnovit. Pro získání barevného dokumentu otevřete soubor s barevnými obrázky nebo papírový dokument naskenujte v barevném režimu.
11/2/2018 4:19:14 PM