- English (English)
- Bulgarian (Български)
- Chinese Simplified (简体中文)
- Chinese Traditional (繁體中文)
- Czech (Čeština)
- Danish (Dansk)
- Dutch (Nederlands)
- Estonian (Eesti)
- French (Français)
- German (Deutsch)
- Greek (Ελληνικά)
- Hebrew (עִברִית)
- Hungarian (Magyar)
- Italian (Italiano)
- Japanese (日本語)
- Korean (한국어)
- Polish (Polski)
- Portuguese (Brazilian) (Português (Brasil))
- Slovak (Slovenský)
- Spanish (Español)
- Swedish (Svenska)
- Turkish (Türkçe)
- Vietnamese (Tiếng Việt)
Як урахувати характеристики вихідного документа
Якість розпізнавання багато в чому залежить від якості вихідного зображення. У цій статті ви дізнаєтеся про те, на що слід звернути увагу до розпізнавання документа:
ABBYY FineReader підтримує розпізнавання як одномовних, так і багатомовних, наприклад англо-французьких, документів. Для розпізнавання багатомовного документа необхідно вибрати декілька мов розпізнавання.
Щоб вибрати мови для розпізнавання, відкрийте діалог Налаштування > закладку Мови і позначте один із пунктів:
- Автоматично вибирати OCR-мову зі списку
Мова буде вибиратися автоматично із заданого списку словникових мов. Ви можете змінити склад цього списку. Для цього: - Переконайтеся, що опцію Автоматично вибирати OCR-мову зі списку ввімкнено.
- Натисніть кнопку Выбрать элементы...
- У діалозі Мови позначте потрібні мови та натисніть ОК.
- Натисніть OK у діалозі Налаштування.
- Вкажіть OCR-мови вручну
Виберіть цей пункт, якщо ви хочете вибрати інші мови для розпізнавання.
У діалозі нижче вкажіть одну або кілька мов. Для цього відмітьте пункти з відповідними назвами мов. Якщо ви часто використовуєте якусь комбінацію мов, то створіть нову групу, яка містить ці мови.
Якщо потрібної мови немає у списку, можливо:
- Ця мова не підтримується системою ABBYY FineReader.
 Повний список мов подано в розділі «Підтримувані мови розпізнавання».
Повний список мов подано в розділі «Підтримувані мови розпізнавання». - Мова не підтримується вашою копією програми. Повний перелік доступних вам мов наведено в діалозі Ліцензії (Довідка > Про програму... > Інформація про ліцензії).
У процесі розпізнавання можна використовувати не тільки визначені мови та групи мов, але й створити нову мову або об’єднати наявні мови в нову групу та під час розпізнавання підключити саме їх. Див. також «Нерозпізнані символи».
Документ може бути надруковано на різних пристроях, наприклад на друкарській машинці або факсимільному апараті. Якість розпізнавання таких документів може бути різною. Можна домогтися вищої якості розпізнавання, встановивши відповідний тип документа в діалозі Налаштування.
Для більшості текстів тип документа визначається автоматично. Цьому відповідає значення Авто, встановлене в групі Тип документа у діалозі Налаштування (меню Інструменти > Налаштування... > закладка Розпізнавання). При цьому ви можете обробляти документ у кольоровому або чорно-білому режимі.
За потреби ви можете вибрати інший тип друку в цій групі.
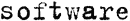 |
Фрагмент сторінки, надрукованої на друкарській машинці. Ширина літер однакова (порівняйте, наприклад, літери «w» і «t»). Для таких текстів установіть значення Друкарська машинка. |
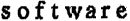 |
Фрагмент сторінки, видрукуваної на факсимільному апараті. Штрихи літер подекуди не надруковані, є шуми та викривлення літер. Для таких текстів установіть значення Факс. |
Після розпізнавання текстів, надрукованих на друкарській машинці або факсі, не забудьте знову вибрати значення Авто під час повернення до друкарського тексту.
Для успішного розпізнавання документа, надрукованого з поганою якістю, може знадобитися змінити налаштування сканування. Такий документ може містити багато «сміття», нечіткі межі літер, кутасті, нерівні літери з дефектами, перекіс рядків, зсув і неявні межі чорних розділювачів таблиць.
| Факс | Газетна сторінка |
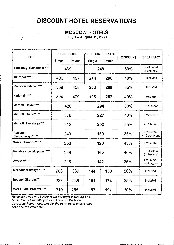 |
 |
Такі документи рекомендується сканувати у відтінках сірого. У такому разі вам не потрібно буде підбирати яскравість сканування, програма зробить це за вас автоматично.
Сканування у відтінках сірого забезпечує вищий ступінь збереження інформації про літери сканованого тексту. Це призводить до поліпшення якості розпізнавання документів середньої та низької якості друку. Ви також можете усунути деякі дефекти вручну, використовуючи інструменти з обробки зображення у вікні OCR-редактора в редакторі зображень. Див. також «Обробка зображень».
Якщо під час розпізнавання документів немає потреби зберігати кольорові ілюстрації та колірне оформлення документа, ви можете обробляти документ у чорно-білому режимі. Це дозволить суттєво зменшити розмір документа і скоротити час на розпізнавання. Однак у деяких випадках для зображень із низькою контрастністю можливе погіршення якості розпізнавання. Не рекомендується обробляти в чорно-білому режимі фотографії, журнальні сторінки та документи, які написано ієрогліфічними мовами.
Порада. Ви також можете скоротити час обробки кольорових і чорно-білих документів, вибравши Швидке розпізнавання на закладці Розпізнавання діалогу Налаштування. Докладніше про режими розпізнавання див. у статті «Параметри розпізнавання».
Як задати кольоровий режим під час сканування документа див. у статті «Рекомендації щодо сканування».
 Після вибору чорно-білого режиму відновити колірне оформлення документа не вдасться. Щоб отримати кольоровий документ, відкрийте файл, що містить кольорові зображення сторінки, або заново відскануйте паперовий документ у кольоровому режимі.
Після вибору чорно-білого режиму відновити колірне оформлення документа не вдасться. Щоб отримати кольоровий документ, відкрийте файл, що містить кольорові зображення сторінки, або заново відскануйте паперовий документ у кольоровому режимі.
11/2/2018 4:20:06 PM