- English (English)
- Bulgarian (Български)
- Chinese Simplified (简体中文)
- Chinese Traditional (繁體中文)
- Czech (Čeština)
- Danish (Dansk)
- Dutch (Nederlands)
- Estonian (Eesti)
- French (Français)
- German (Deutsch)
- Greek (Ελληνικά)
- Hebrew (עִברִית)
- Hungarian (Magyar)
- Japanese (日本語)
- Korean (한국어)
- Polish (Polski)
- Portuguese (Brazilian) (Português (Brasil))
- Slovak (Slovenský)
- Spanish (Español)
- Swedish (Svenska)
- Turkish (Türkçe)
- Ukrainian (Українська)
- Vietnamese (Tiếng Việt)
Riconoscimento in background
L'Editor PDF consente di eseguire ricerche e copiare il testo e le immagini contenuti in documenti PDF privi di livello di testo, come documenti digitalizzati e documenti generati da file immagine. Questo è possibile grazie a un processo OCR che viene eseguito in background.
Per impostazione predefinita, il riconoscimento in background è attivo e viene automaticamente avviato all'apertura di un documento PDF.
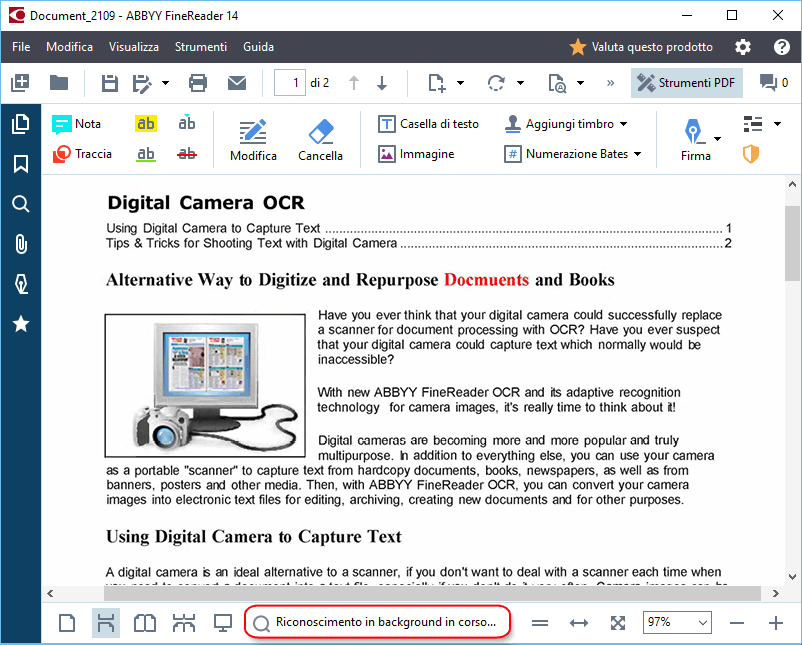
Il processo di riconoscimento in background non cambia il contenuto del file PDF, ma aggiunge un livello di testo temporaneo che non è disponibile se si apre il documento in altre applicazioni.
 Se si desidera rendere il documento ricercabile in altre applicazioni, è necessario salvare il livello di testo creato dal processo di riconoscimento in background. Per fare ciò, fare clic su File > Riconosci documento > Riconosci documento... Consultare anche: Riconoscimento del testo.
Se si desidera rendere il documento ricercabile in altre applicazioni, è necessario salvare il livello di testo creato dal processo di riconoscimento in background. Per fare ciò, fare clic su File > Riconosci documento > Riconosci documento... Consultare anche: Riconoscimento del testo.
 Importante! Nel caso in cui le operazioni di ricerca e di copia non funzionino correttamente, controllare di aver specificato le lingue OCR corrette per il documento. Consultare anche: Caratteristiche dei documenti da considerare prima del riconoscimento.
Importante! Nel caso in cui le operazioni di ricerca e di copia non funzionino correttamente, controllare di aver specificato le lingue OCR corrette per il documento. Consultare anche: Caratteristiche dei documenti da considerare prima del riconoscimento.
 Per disattivare il riconoscimento in background, deselezionare l'opzione Attiva riconoscimento in background nell'editor PDF nella finestra di dialogo Opzioni.
Per disattivare il riconoscimento in background, deselezionare l'opzione Attiva riconoscimento in background nell'editor PDF nella finestra di dialogo Opzioni.
Il processo di riconoscimento in background non può essere eseguito su computer dotati di processore single-core.
11/2/2018 4:19:28 PM