- English (English)
- Bulgarian (Български)
- Chinese Simplified (简体中文)
- Chinese Traditional (繁體中文)
- Czech (Čeština)
- Danish (Dansk)
- Dutch (Nederlands)
- Estonian (Eesti)
- French (Français)
- German (Deutsch)
- Greek (Ελληνικά)
- Hungarian (Magyar)
- Italian (Italiano)
- Japanese (日本語)
- Korean (한국어)
- Polish (Polski)
- Portuguese (Brazilian) (Português (Brasil))
- Slovak (Slovenský)
- Spanish (Español)
- Swedish (Svenska)
- Turkish (Türkçe)
- Ukrainian (Українська)
- Vietnamese (Tiếng Việt)
זיהוי רקע
עורך PDF מאפשר לך לחפש ולהעתיק טקסט ותמונות במסמכי PDF ללא שכבת טקסט, כגון מסמכים סרוקים ומסמכים שנוצרו מקובצי תמונה. ניתן לעשות זאת הודות לתהליך זיהוי התווים האופטי (OCR) שפועל ברקע.
זיהוי רקע מוגדר כזמין כברירת מחדל, ומתחיל לפעול באופן אוטומטי בעת פתיחה של מסמך PDF.
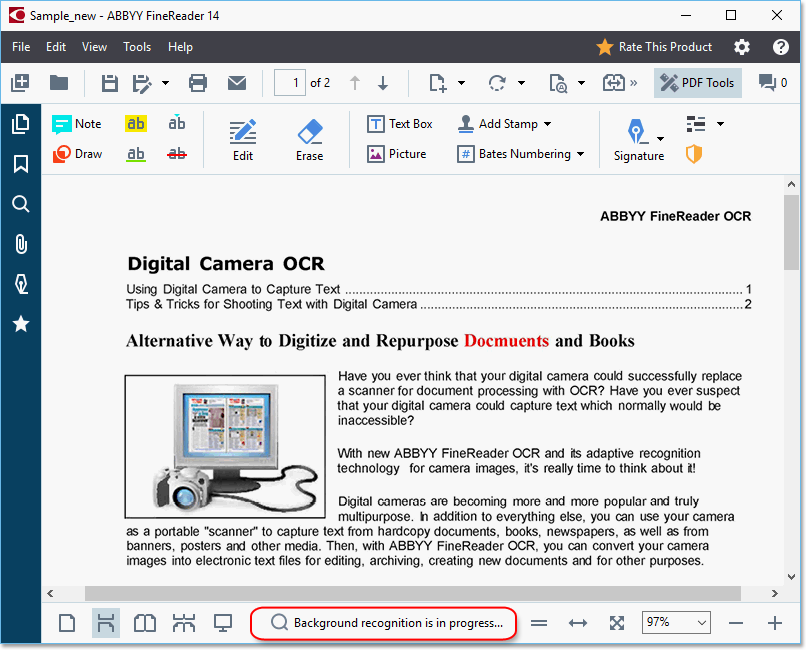
תהליך זיהוי הרקע לא משנה את תוכן קובץ ה-PDF. במקום זאת, הוא מוסיף שכבת טקסט זמנית, שלא תהיה זמינה כשתפתח את המסמך ביישומים אחרים.
 אם ברצונך להפוך את המסמך למסמך שניתן לחפש בו ביישומים אחרים, עליך לשמור את שכבת הטקסט שנוצרה על-ידי תהליך זיהוי הרקע. לשם כך, לחץ על File > Recognize Document > Recognize Document...ראה גם: זיהוי טקסט.
אם ברצונך להפוך את המסמך למסמך שניתן לחפש בו ביישומים אחרים, עליך לשמור את שכבת הטקסט שנוצרה על-ידי תהליך זיהוי הרקע. לשם כך, לחץ על File > Recognize Document > Recognize Document...ראה גם: זיהוי טקסט.
 חשוב! אם פונקציות החיפוש או ההעתקה לא פועלות כראוי, ודא שנבחרו עבור המסמך השפות הנכונות של זיהוי תווים אופטי (OCR). ראה גם: תכונות מסמך שיש להביא בחשבון לפני זיהוי תווים אופטי (OCR).
חשוב! אם פונקציות החיפוש או ההעתקה לא פועלות כראוי, ודא שנבחרו עבור המסמך השפות הנכונות של זיהוי תווים אופטי (OCR). ראה גם: תכונות מסמך שיש להביא בחשבון לפני זיהוי תווים אופטי (OCR).
 כדי להשבית את זיהוי הרקע, נקה את האפשרות Enable background recognition in the PDF Editor בתיבת הדו-שיח Options.
כדי להשבית את זיהוי הרקע, נקה את האפשרות Enable background recognition in the PDF Editor בתיבת הדו-שיח Options.
תהליך זיהוי הרקע לא מסוגל לפעול במחשבים עם מעבד ליבה בודדת.
02.11.2018 16:19:24