NLP Model Training
ABBYY FlexiCapture 12 SDK uses NLP (Natural Language Processing) models to extract information from unstructured texts. NLP models trained on your sample documents determine what entities and segments should be extracted from a document, which allows for the information that you need to be extracted more efficiently.
You can create and train one or more NLP models depending on the variety of your documents, as well as the complexity and amount of the information that you need to extract. A segmentation model uses the text of the entire section to find the required paragraphs, while an extraction model finds entities in text fragments.
Preparing for training
NLP technology is used in ABBYY FlexiCapture SDK as a part of a Document Definition, so you need to create a new Document Definition or get it from the collection.
- Get the Document Definition from the DocumentDefinitions collection of your Project. Switch the Document Definition to editing mode by calling the CheckOut method of the DocumentDefinitions object and get the sections of the Document Definition using the Sections property of the DocumentDefinition object.
- Obtain the NLP models collection using the NlpModels property of the SectionDefinition object.
- Get the collection of the extraction models using the ExtractionModels property of the NlpModels object or get the handler of the segmentation model using SegmentationModelHandler property of the NlpModels object. If you have an existing extraction model, you can load it using the LoadFromFile method of the ExtractionModels object.
- Or you can create a new one:
- To extract entities, you need an entity extraction model. Call the AddNew method of the ExtractionModels object.
- If you want to improve the accuracy and speed of entity extraction using segmentation, create a segmentation model by calling AddNewSegmentationModel method of the SegmentationModelHandler object.
- For both models:
- Make sure the training flag (AllowTraining property) is set to TRUE if you want to train your NLP model.
- Specify the field from which to extract the entity using the Source property.
 Note: For a segmentation model, the value of the Source property is a specific Document Definition section to which the segmentation model belongs.
Note: For a segmentation model, the value of the Source property is a specific Document Definition section to which the segmentation model belongs. - Specify the language of the text to be extracted using the Language property.
- Specify the output fields using the ResultFields property. The output fields will contain information extracted by the model from your documents.
- Call the CheckIn method of the DocumentDefinitions object.
C# code
Training NLP models
Once your NLP model has been loaded or created, you need to train it on some sample documents.
- Add a new training batch using the AddNew method of the FieldsExtractionTrainingBatches object.
- Set the value of the IsNlpTrainingBatch property of the FieldsExtractionTrainingBatch object to TRUE to define a training batch as a batch for NLP training.
- Add images for NLP model training to the batch. Call the Recognize method of the Batch object to match the Document Definition and recognize all the documents in the batch.
- Mark up the layout of the fields that will be trained. Assign the correct region to each field by calling the AddNew method of the FieldRegions object.
- Train field extraction. Get the FieldsExtractionTrainer object from the training batch and call its Train method.
C# code
You can now use the trained NLP model to process your documents.
 Important! To recognize documents using NLP technology, the NLP module must be installed. If no NLP components are found, you cannot use the NLP models.
Important! To recognize documents using NLP technology, the NLP module must be installed. If no NLP components are found, you cannot use the NLP models.
NLP model training limitations
- You can only have one segmentation model for each Document Definition section
- Fields used in training (fields of the ResultFields property) cannot be nested more than one level deep, i.e. must have a flat structure: a simple field or a field inside a group of fields. Fields inside a group that is part of another group cannot be trained. The first nesting level is a source field, and here are the possible options of the source field values and fields structure:
- The value of the Source property is a Document Definition section, the value of the ResultFields property is a flat list of repetitive and non-repetitive fields and groups of non-repetitive fields:
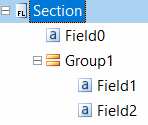
- The value of the Source property is a segmentation model field or a field retrieved by a flexible description, the value of the ResultFields property is a flat list of repetitive and non-repetitive fields and groups of non-repetitive fields:
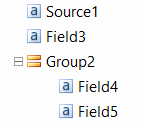
- The value of the Source property is a non-repetitive field in a repetitive group, the value of the ResultFields property is a flat list of repetitive and non-repetitive fields and groups of non-repetitive fields inside the same group:
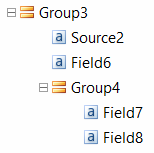
In this case, it is recommended that the non-repetitive fields be within the same sentence for each group. - The value of the Source property cannot be a repeatable field. You can use a non-repetitive field in a repetitive group instead.
Samples
See the NLP Model Training code sample for an implementation of this scenario.
See also
8/15/2023 1:19:30 PM