NLP Training Objects
Natural Language Processing (NLP) is a subfield of artificial intelligence and computational linguistics. NLP is concerned with computer analysis and synthesis of natural languages. One possible practical application of NLP is the extraction of meaningful data from text.
ABBYY FlexiCapture SDK uses NLP technology to process unstructured documents such as contracts, letters, and orders. The essence of the process is extracting so-called entities. An entity is a field or a group of fields containing information that needs to be extracted by means of NLP technology. Using a trained NLP model, you can extract, for example, such kind of entities: people, companies, places, amounts, and dates. To improve the accuracy and speed of entity extraction you may want to segment a document into clear parts of certain pages or paragraphs before extracting information from it. This process is called segmentation, and requires a trained segmentation model.
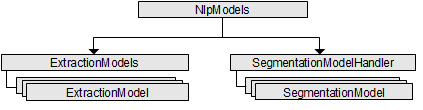
NLP models determine what entities and segments should be extracted from a document. Trained NLP models are used in ABBYY FlexiCapture SDK for extracting information from unstructured texts.
The section describes the following objects:
See also NLP Model Training. To learn about the limitations for training, see NLP model training limitations.
The hierarchy of the objects
15.08.2023 13:19:30