Glossary
A
ABBYY FlexiCapture
A software solution for single-flow input of data from various document types structured (fixed forms), semi-structured (flexible forms and documents) and unstructured (free-format documents).
ABBYY FlexiLayout Studio
A program allowing you to create a FlexiLayout of the document structure, which can then be used for automatic document recognition.
ABBYY FormDesigner
ABBYY FormDesigner is used to design layouts of machine-readable forms. Once replicated and filled out, these forms can be processed with the ABBYY FlexiCapture automated form input system. Form layout design is an important stage, since the quality of the designed layout (its machine readability) determines the effectiveness of all subsequent processing stages: scanning, recognition, verification, and export.
ABBYY FlexiCapture for Invoices
An ABBYY FlexiCapture is an easy-to-use, intelligent software solution for processing invoices.
ADF
Automatic Document Feeder. A device for automatic document feeding that enables you to scan any number of documents without performing additional manual operations.
Administrator
A user of ABBYY FlexiCapture who is authorized to configure the program for document input: creating and editing Document Definitions and import profiles.
Alphabet
A set of characters used in the language being described.
Anchor
A static element in the form of a black square, rectangle, cross or corner intended for Document Definition matching.
Details...
Anchor barcode
A static element representing a barcode that is not intended for data extraction. An anchor barcode can be used for Document Definition matching or identification.
Anchor text
A static element representing a text that is present on a blank form and is not intended for data extraction. This may be any explanatory text or header. Anchor text can be used for Document Definition matching or identification.
Angle
An anchor shaped as an angle.
Annex
Pages that do not contain fields, but are included in document assembly. No data is extracted from these pages, but they may be saved as images or PDF searchable files. See Creating Document Definitions for documents with annexes.
Assembly error
This error occurs when a document that was created during document assembly contains pages from other documents, when its own pages are in the wrong order, or when the values of key fields in the document's pages do not match.
Auto-learning
The ability of ABBYY FlexiCapture to automatically learn to detect new fields and identify document types.
B
Barcode
A machine-readable form element represented as alternating white and black bars of a certain length, which encode digital information. A barcode in a document may be used to extract information (barcode field) or to match and identify a Document Definition (anchor barcode).
Barcode field
A Document Definition field containing a barcode intended for recognition.
Barcode recognition
Conversion of a graphic barcode image to numbers or text.
Batch type
The property of a batch that defines how documents in the corresponding batches are to be processed. See Batch types.
Black-and-white line form
A form in which borders of information fields are formed by ordinary lines that do not disappear during scanning.
Black square
An anchor shaped as a black square.
Brightness
A threshold of light sensitivity that determines at which point the scanner detects grayscale halftones as white.
C
Checkmark
A machine-readable form element that is filled with a mark (tick, cross, dot, inked out, etc.) by the person filling out a form.
Checkmark field
A Document Definition field containing a checkmark.
Checkmark group
An element of a machine-readable form uniting several checkmarks located nearby. One or several checkmarks can be selected in a checkmark group.
Checkmark group field
A Document Definition field containing a checkmark group.
Classifier
A project created in FlexiLayout Studio and intended for preliminary identification of pages prior to applying Document Definitions as well as for selecting the matching FlexiLayout or layout alternative.
Classifier F-measure
A combined measure of precision and recall for document classification. It is expressed as a number between 0 and 1 or as a percentage between 0% and 100%.
F-measure for a category is calculated as (β^2 + 1) * P * R / (β^2 * P + R), where P is the precision for the category, R is the recall for the category, and β is a free parameter which determines the relative weighting of precision and recall for the given model. Maximum value = 1 (100%) when P = R = 1 (100%).
F-measure for a test or training batch is calculated as (β^2 + 1) * P * R / (β^2 * P + R), where P is the precision for the test or training batch, R is the recall for the test or training batch, and β is a free parameter which determines the relative weighting of precision and recall for the given model.
Code page
A table of values that describes the character set for a particular language.
Color background form
A form in which all information fields are white rectangles against a color background that disappears during scanning.
Contrast
Ratio between the brightness of the darkest and lightest areas on an image.
Control
A text, field or button element on the data form.For details, see Insert Control.
Corrected checkmark
A checkmark that was selected mistakenly and then inked out. If the option Allow corrections is enabled for the checkmark field, the program will recognize the inked out checkmark as unselected.
Cross
An anchor shaped as a cross.
Custom data type
User-defined data type. See Creating custom data types.
D
Database lookup
Matching recognized data against corresponding database records.
Data set
Data used for automated document checks. A data set may be stored as a table in ABBYY FlexiCapture and synchronized according to a schedule or retrieved from an external source.
Data type
A field attribute describing known constraints of possible field values. It is used during field recognition to reduce the number of possible recognition variants.
Details...
Description file
An auxiliary file that defines how a batch is formed when images are being added from a Hot Folder. For details see Description file.
Dictionary
A list of words used to determine a specific data type.
Details...
Document
A combination of one or several page images and data extracted from them.
Document batch
A combination of documents grouped by the user. A batch normally contains the stack of documents scanned in a single pass or imported from a particular folder. See Document batches.
Document class
A set of documents or pages that share several common characteristics.
Document data
Data captured after processing (recognition, verification and editing of recognition results) of document page images.
Document Definition
A Document Definition defines the principles of identification and processing of a particular type of document and contains:
- The document structure, i.e. a description of the allowable order of pages for documents of this type, which defines how documents should be assembled
- Definitions of document sections
- A list of rules that field data should satisfy
- The locations of fields and their signatures in the data window (data form view)
- Document export settings
- Document processing settings
Document Definition identification
A process of selecting the required Document Definition with the help of identifiers.
Document Definition matching
A process of selecting a Document Definition and matching its fields against an image.
Document Definition publication
Allowing access to a new Document Definition version once it has been edited. A published version participates in the processing of documents from work batches, while an unpublished, local version can participate only in the processing of Document Definitions from test batches. See Editing and publishing a Document Definition.
Document Definition Section
A component of a Document Definition. Corresponds to one or several pages containing a logically complete set of fields. Fields within one section can continue from one page to the next (for example, multipage tables), while field sets from various sections do not intersect.
A section definition can be flexible or fixed.
Document identification
The process of assigning documents to one of several predetermined document types.
Document set
A set of logically related documents that are used for a specific purpose. For instance, a business process may be initiated by a set of documents provided by an applicant consisting of a filled out application form and some accompanying documents. Depending on the information provided by the applicant on the application form, some of the accompanying documents may be optional while others must be enclosed with the application.
Document text
All of the text from the document that was captured from the document during preliminary recognition, before the FlexiLayout is applied. You may choose to save this text (requires additional space on the hard disk) so that it can be used during verification.
Document type
A number of documents that have several characteristics in common and play a specific role in business processes.
Some examples of document types are invoices, contracts and passports.
Document variant
A number of documents belonging to the same type that share several characteristics.
Examples of document variants include invoices from different vendors and credit statements from the same bank.
Dot-matrix printer
A type of recognizable text that represents a text printed with a dot-matrix printer.
dpi
Dots per inch. Number of dots per inch; a measurement unit of image resolution.
E
Entity
A field or a group of fields containing information that needs to be extracted by means of NLP technology. Examples of entities include: people, companies, places, amounts, and dates.
Environment variable
A string that is used to store text, e.g. system settings. Environment variables may be used to store database connection strings and variables that are used when specifying the names of exported files.
Error / warning
The error / warning occurs when data extracted from one or more fields does not satisfy rules that are applied during automatic checks or does not match the specified format. There are two different types of errors and warnings:
- single-field error / warning are generated by rules and formats that affect one fields;
- multi-field error / warning are generated by rules that affect multiple fields.
Explanatory text
A machine-readable form element that represents a descriptive text (form name, field names, explanations to fields, etc.).
Export
A process of transferring processed data to an external information system or file.
Export profile
A set of settings that determines what is done with processed data: the format of output files, the output path, export conditions, etc.
External database
A text file or an ODBC-compatible database that stores reference data. Reference data may include the possible values of captured fields or information required for capturing fields.
F
Field
A document element intended for data extraction. Fields may be simple (without an internal structure) or composite, such as the table field where each cell can be viewed as a separate subordinate field of the table. See Creating Document Definition fields.
Field region
An image region highlighted in the Document Definition and intended for data extraction.
Field verification
A verification mode whereby recognized characters are submitted for verification within the context of a field.
Details...
Field with several instances
A field used to describe several objects of the same type (recurring objects). In essence, these multiple objects are one and the same field and share the same properties. Fields with several instances are used to avoid the need to create several identical fields. Fields with several instances are exported to separate files or database tables. See Fields with several instances.
Field with several regions
A field consisting of several regions on the image. Such regions may be located at a distance from one another and even on different pages. Values from all regions belonging to the same field are combined and exported together as one field. Normally used for objects located on several pages, such as large tables. See Fields with several regions.
Field without a region
A field detected in a Document Definition but not having a region on the image. See Fields without a region.
Fixed form
A document with fixed information fields whose formatting, number and layout are strictly defined and do not change from one document instance to another.
Fixed Document Definition
A definition of a document or its section designed for processing fixed forms. Fields in a fixed Document Definition have fixed locations.
FlexiLayout
Description of the semi-structured document structure. This description is designed with ABBYY FlexiLayout Studio and exported to ABBYY FlexiCapture. File format *.afl. FlexiLayout is a kind of instruction for detecting and identifying fields in a flexible form.
FlexiLayout variant
A FlexiLayout for a document variant that was either developed specifically for this document variant or was trained on this document variant. Used in conjunction with a generic FlexiLayout.
Flexible Document Definition
A definition of a document or its section designed for processing semi-structured documents. Created by attaching a FlexiLayout. Fields in such a Document Definition do not have fixed locations. They are detected with the help of a FlexiLayout. See Creating a Document Definition for semi-structured document processing.
Form
A document comprising one or several pages designed to be filled out by a person by hand or using any other printing technique.
Framed text
Type of text marking where a frame delimits the text.
Show...
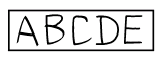
Framed text over a comb
Type of text marking where text is delimited by a frame with a bottom boundary shaped as a comb.
Show...
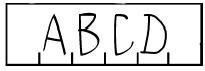
G
Gray background form
A form in which all information fields are white rectangles against a gray background that disappears during scanning.
Group verification
A verification mode whereby identically recognized characters are submitted for verification in groups.
Details...
H
Hand-printed text
A type of recognizable text that represents a text printed by hand in distinct type.
Handwritten text
A type of recognizable text with letters joined up or partially joined up. Note: Currently, only English handwritten text can be recognized.
Note: Currently, only English handwritten text can be recognized.
Hot folder
A folder on the hard drive of a local or remote computer, which is used for importing images. It is normally used for periodically recurring image uploads without the user's involvement. See Image import profiles.
I
Identifier
A static element used for certain selection of a Document Definition from among several Document Definitions with identical locations of anchors. The option Use for Document Definition identification must be enabled in the properties of such static elements.
Identity provider
A third-party system, such as Azure AD, OneLogin or Okta, that manages identity information and provides authentication services to its clients, enabling an end-user to access all authorized resources in his/her local area network by entering their credentials only once.
Ignored character
A character occurring inside words (for example, a bullet) or a soft hyphen character (tabulation, etc.) whose presence does not prevent the program from attributing the word to a recognizable data type.
Details...
Image
An electronic image of a scanned page from a hardcopy document.
Image despeckling
Removal of noise from the image. Noise can appear during scanning, and it is recommended that it be removed to enable better data recognition. During despeckling, the program also removes background dots or boundary lines of raster forms.
Image import
A process of adding images to a batch for processing. Import can be performed by adding images from files, from a scanner or using import profiles. See Adding page images.
Image rotation
Rotation of an image around its center.
Import profile
A combination of settings used to add images to a batch: import source, image processing options, Hot Folder cleanup options, etc. See Image import profiles.
Incorrectly recognized character
Status automatically assigned to a character in the process of recognition if it has been recognized with a considerable degree of uncertainty.
Index field
A field whose value is used to index documents for sorting and search purposes. See Index fields.
Inverted image
An image with light-colored text against a dark background.
Invoice
A document that lists goods that have been supplied, their quantity, price, characteristics (such as color, weight, etc.), shipment conditions, and details of the parties. Invoices can be processed by means of a separate solution, ABBYY FlexiCapture for Invoices. See ABBYY FlexiCapture for Invoices.
ICR, Intelligent Character Recognition
This refers to technologies or systems designed for mass processing of documents filled with handprinted letters and numbers, i.e. recognition of handprinted characters.
K
Key field
A field that enables automatic checking of page assembly into documents. The values of key fields must be identical on all pages of the same document.
L
Language (local)
A field property that determines the writing language and relevant sets of regional parameters (such as the date or address writing style).
Layout
The location of fields on a document image. Layouts can be generated automatically or created manually. See also Reference layout.
Letters in frames
Type of text marking where every character is delimited by a frame; frames are not isolated from one another.
Show...

Letters in isolated frames
Type of text marking where every character is delimited by a frame; frames are isolated from one another.
Show...

Letters over a comb
Type of text marking where a "comb" delimits the text.
Show...
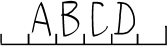
M
Machine-printed text
A type of recognizable text that has been printed using typographic equipment or a laser or ink-jet printer with a minimum resolution of 300 dpi.
Machine-readable form
A form designed especially for automated input. It contains work elements (anchors, barcodes, lines, etc.) that are required to process it successfully.
Manual entry field
A Document Definition field containing unrecognizable text (for example, text consisting of fused letters) that has to be entered from the keyboard.
MRC (Mixed Raster Content)
A compression method used for images that contain both text and raster fragments. The image is analyzed into fragments and an optimal compression algorithm is selected for each. This approach provides better compression ratios while maintaining the visual quality of images.
Monospaced text
Type of text marking where each letter is located within a frame of the same height and width, but the frame border disappears during scanning.
Multipage document
A document made up of several pages.
Multitenancy
A feature allowing several independent users to use ABBYY FlexiCapture. The data of each tenant is completely isolated from other tenants and the system allocates a portion of its resources to each tenant.
N
NER (Named-Entity Recognition)
An information extraction job based around searching for attributes in unstructured text and classifying them into predefined categories.
NLP (Natural Language Processing)
A subfield of artificial intellingence and mathematical linguistics. Concerned with computer analysis and synthesis of natural languages. One possible application is the extraction of meaningful information from text. Includes the following: machine translation, chat bots, classification, tonality analysis, data extraction, etc.
NLP model
A mechanism that determines what entities and segments should be extracted form texts and how. The subject area and the extraction algorithm are selected when training an NLP model.
O
OCR (Optical Character Recognition)
Optical recognition of machine-printed texts.
OMR (Optical Mark Recognition)
This technology enables ABBYY FlexiCapture to both recognize ordinary marks (ticks, crosses, etc.) on forms with a high degree of certainty and to correctly identify marks that were made by mistake and then inked out.
Operator
A user of ABBYY FlexiCapture who is tasked with document entry: adding images, performing recognition and verification, exporting recognized data.
Operator role
The property of a user account in ABBYY FlexiCapture, which determines what data are accessible to the user and what actions can be performed on these data. See Operating a configured project.
Overlay
The process of combining a scan of a filled-out form with an image of a blank example of the same form in the Document Definition editor.
P
Page
Image of a paper document page and results of its processing.
Page layout
A scheme showing the location of fields on an image.
Page orientation
Page location relative to the standard alignment: top to bottom, left to right. Page orientation can be determined automatically during page image recognition; to this end ABBYY FlexiCapture allows you to specify possible orientations.
Picture
An element of a machine-readable form that is not subject to recognition but intended for export in the form of a graphic object (for example, a file).
Picture field
A Document Definition field containing a picture.
Precision
A characteristic that lets the user evaluate the automatic classification quality. It is calculated by dividing the number of correctly identified class A documents by the total number of all documents identified as class A (both correctly and incorrectly).
Prerecognition
Full-text recognition of document images to facilitate field detection by means of a Document Definition.
Processing power
The average number of pages, documents or batches processed during a specific period of time.
Processing stage
A workflow stage where certain actions are performed on a document or batch (either automatically or by an Operator). See Processing stages and queues.
Prohibited character
A character that you are certain will not occur in the data being recognized.
Details...
Project
A project is a single environment uniting the document batches and settings required to process them, such as Document Definitions, import profiles, etc. See Creating a project.
Q
Queue
Documents grouped into tasks and/or batches, waiting to be processed at a certain processing stage. See Processing stages and queues.
R
Raster form
A form in which information fields are represented as white rectangles against a gray background consisting of raster lines or rectangles delimited by raster lines.
Raster line
A line consisting of equally spaced dots.
Recall
A characteristic that lets the user evaluate the automatic classification quality. It is calculated by dividing the number of correctly identified class A documents by the total number of all class A documents.
Recognition
A process of matching image elements against specific characters.
Recognition language
A language used by ABBYY FlexiCapture for text recognition.
Reference classes
A reference class is a class that has been assigned to a document by an expert during manual classification. Both a section of a document, as well as a document variant, can be a reference class.
Reference layout
A user-created layout that is used as a reference for automatically created layouts. This comparison serves to evaluate how well the program detects field regions.
Regular expression
Description of the structure of a word or any entered value using a special language. The program allows you to specify not just the set of allowable characters, but also the structure of field contents. You can describe the structure with a regular expression when setting constraints for a text field or when creating a custom data type. See Alphabet used in regular expressions.
Resolution
Image parameter. Resolution is measured in dots per inch (dpi).
Result classes
A result class is a class that has been assigned to a document during an automatic classification.
Rule validation
An automatic check of recognized data against preset rules. See Rule validation.
Rules
Certain conditions imposed on data in fields and automatically checked by the program. See Rule validation.
S
Scanning
A process of getting an electronic image of a paper form using a scanner.
Segment
A text fragment consisting of one or more paragraphs that contains data that needs to be extracted. A segment can also be a field that needs to be extracted (for example, conditions for terminating an agreement).
Segmentation
The process of identifying segments. Segmentation precedes information extraction and is useful in the case of large documents, as it narrows down a search for entities to specific text fragments.
Section
A logically distinct part of a document that contains a set of extractable fields. Sections are used for various purposes during the recognition process, such as assembling documents from pages. Sections can include a single page or multiple pages and can be fixed or flexible. See Creating Document Definitions for multipage documents.
Semi-structured document
Document containing a set of information fields whose design, number and layout may vary significantly in different instances of the document. See What types of documents can be processed with ABBYY FlexiCapture.
Separator
A machine-readable form element representing a vertical or horizontal line.
Service field
A field that does not have a region on the document image. The values of service fields are determined automatically based on data from the source indicated in their properties. See Service Fields.
Set of allowable characters
A set of characters occurring in the data type being recognized.
Details...
Simple text
A type of text marking where text is inserted in a block without any delimiters.
Single-flow data input
Automated data extraction from analog (printed) and digital (scanned image) documents.
Single-flow document input
Automated conversion of hardcopy documents into electronic form.
SLA (service level agreement)
An agreement governing the provision of IT services. In ABBYY FlexiCapture 12, an SLA agreement governs the deadlines for processing batches.
Static elements
Unrecognizable elements intended for Document Definition matching and identification. Such elements are: anchors, anchor text, separators, anchor barcodes.
Summary section
The summary section is a Document Definition section that displays of all the main fields in a document set. This makes it much easier for Operators to review documents in a set because they will be able to see all of the errors and low-confidence data in one place and only open the documents that need to be reviewed instead of opening each document.
T
Table
Data arranged in a two-dimensional grid that is not necessarily visible. The program processes tables consisting of columns with same-type data and repeating rows.
Table field
A Document Definition field containing a table. It is a composite field, with every table column representing a set of fields of the same type: text, checkmarks, barcodes or pictures.
Task
A set of documents from the same batch to be processed together. Depending on the project settings and the processing stage, a task may contain different numbers of documents. If a processing stage requires a batch to be processed in its entirety, the whole batch is included in the task. When verification tasks are formed automatically, each task contains 10 documents (if a batch contains fewer than 10 non-verified documents, they are all processed as one task).
Tenant
An isolated instance of ABBYY FlexiCapture that can be used independently from other users.
Test batches
Document batches designed for Document Definition testing and configuration. Local copies of document batches are used to process test batches. See Document batches.
Text field
A machine-readable form element designed for text entry when filling out a form.
Text field marking
A graphic element delimiting a text field: frame, comb, line.
Text marking
The design of a page region intended for text input. See samples of text formatting in the Entry field topic.
Text orientation
Direction of text in a field relative to the page.
Text recognition (OCR, ICR)
Conversion of a graphic image to text.
Text sample
A file containing samples of all alphabet characters.
Training [Document Definition]
A feature in ABBYY FlexiCapture for Invoices that allows users to train the program to capture data from specific kinds of invoices. Training improves the quality of data capture and can be done either when setting up the program or while processing invoices.
Training batches
A batch of documents used for training and testing a Document Definition for a specific document variant. Training a Document Definition on a training batch creates a FlexiLayout variant. See also document batch, document variant, FlexiLayout variant.
Typewriter
A type of recognizable text that represents a text printed with a typewriter.
U
Underlined text
Type of text marking where underlining delimits the text.
Show...
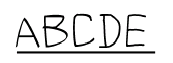
User dictionary
An auxiliary dictionary created by the user which contains words not included in the built-in dictionaries. Built-in dictionaries can be supplemented with a user dictionary to improve the quality of data capture. Typically, a user dictionary will contain specialized terms, abbreviations, company names, etc.
Unrecognizable region
An image region excluded from recognition. An unrecognizable region is required to exclude a region with explanatory text or picture that complicates field recognition. See Excluding a region from recognition.
Unstructured document
A document containing information presented in a free form. Examples of such documents are contracts, letters, orders, graphs. See Creating Document Definitions for unstructured and semi-structured documents.
V
Vendor
A legal or physical person that sells goods or services. Vendors issue invoices for their goods and services. Data from invoices can be captured by means of ABBYY FlexiCapture for Invoices.
Verification
Verification consists in checking that the data have been recognized, pages have been assembled into documents correctly, and rules returned no errors. Verification is done on the Data Verification Station (where recognition accuracy is verified) and on the Verification Station (where all types of checks can be performed). See Verification.
W
Work batches
Document batches intended for data input. Only published Document Definitions are used for processing work batches. See Document batches.
Writing style
A manner of writing that is specific to a particular group. For example, the American manner of writing numbers.
Details...
X
XFD
XML Form Definition (*.xfd) a special file format of a form designed with ABBYY FormDesigner. An XML Form Definition format file is used to create Document Definitions in ABBYY FlexiCapture.
12.04.2024 18:16:02