Creating NLP models
Creating document fields
For every entity that you want to extract, a corresponding field should be created in the Document Definition. To create a field:
1. In the Document Definition Editor, right-click the Document Section name and select Create Field.
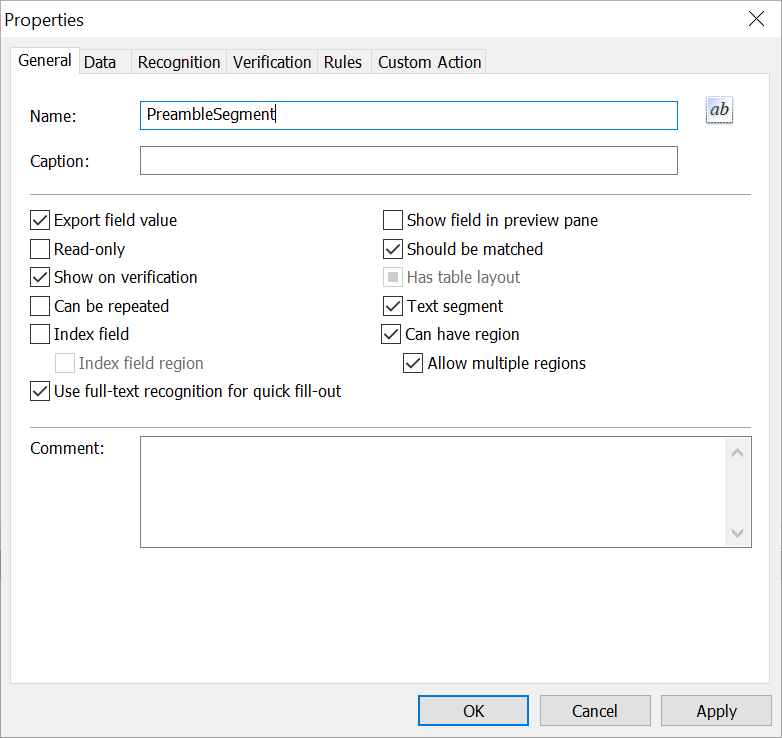
- Create a Text field.
- On the 全般 tab, select the 領域を持つことが可能 option.
- In the 名前 field, specify a name for the field (for example, PreambleSegment).
 重要! Field names must not contain spaces or non-English characters or start with a number.
重要! Field names must not contain spaces or non-English characters or start with a number.
Properties window
Repeat the above steps for each entity.
 注: If segmentation is used, a separate text field should be created for each segment.
注: If segmentation is used, a separate text field should be created for each segment.
For each segment from which entities will be extracted:
- Create a non-repeating field in a repeating group.
- Select the テキストセグメント option in the field properties.
- Select the 複数の領域を許可する option if some of the segments begin and end on different pages.
Creating a segmentation NLP model
Segmentation improves the accuracy and speed of entity extraction. Segmentation is optional. A special NLP model is required to segment documents. 重要! You can have only one segmentation model for each document section.
To create a segmentation model:
- In the Document Definition Editor, right-click the Document Section name.
- Select プロパティ....
- In the dialog box the opens, click the テキスト分析 tab and then click 作成 ....
- In the 名前 field, specify a name for your segmentation model (for example, SegmentationModel).
- In the Model type field, choose セグメンテーション.
- In the 言語 list, select the required language.
Creating a segmentation NLP model
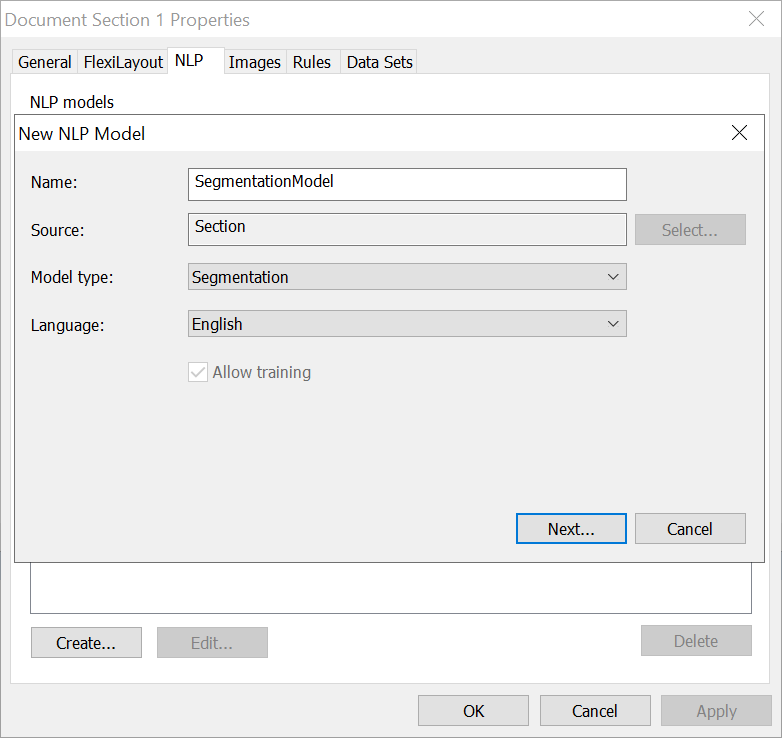
- Click 次....
- In the dialog box that opens, specify all the fields into which the segments will be extracted.
- Click OK.
Once you have created a segmentation model, you need to train it on some sample documents.
注: The トレーニングを許可する option allows you to train your NLP model during document processing. Your NLP model will be trained when you train field extraction using a field extraction training batch. Training results can be either disabled or deleted. To disable training results, right-click the training batch and select the 無効 item on the shortcut menu. To delete training results, right-click the training batch and select the 削除 item on the shortcut menu.
Creating an entity extraction NLP model
To extract entities, you need an entity extraction NLP model that has been trained on manually marked up documents. To create an NLP model:
- In the Document Definition Editor, open the document section properties and click the テキスト分析 tab.
- Click 作成 ....
- Specify a 名前 for your NLP model (for example, EntitiesExtraction).
- For the data source, select either a section (if no segmentation is used) or a segment (if have chosen to use segmentation).
- In the モデルタイプ field, choose 抽出.
- In the 言語 list, select the required language.
- Click 次....
- Choose the result fields that will be extracted from the selected document section or segment.
Repeat steps 1 through 9 for each document segment or section from which entities should be extracted.
- Click Document Definition > 保存 to save your Document Definition.
- Click Document Definition > 閉じる to close the Document Definition editor.
- Click Document Definition > 公開 to publish your Document Definition.
Once you have created an entity extraction NLP model, you need to train it on some sample documents.
注: The トレーニングを許可する option allows you to train your NLP model during document processing. Your NLP model will be trained when you train field extraction using a field extraction training batch. Training results can either be disabled or deleted. To disable training results, right-click the batch and select the 無効 item on the shortcut menu. To delete training results, right-click the batch and select the 削除 item on the shortcut menu.
12.04.2024 18:16:25