Japanese (日本語)
標準の認識オプション
また、標準認識モードで、次のオプションを指定してください:
- ICR フィールドに手書きまたはハンドプリント静的テキストが含まれている場合は、このオプションを有効にします。 ライティングのスタイルは国によって大きく異なるで適切な国を指定する必要があります。
数字のライティングスタイルの例
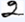

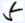


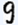
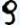
- OCR(印刷)このフィールドの静的テキストが印刷文字の場合は、このオプションを有効にします。ドロップダウンリスト(印刷、ドットマトリクスプリンタ、タイプライターなど)から印刷スタイルを選択します。以下も参照:対応しているテキスト形式。
- 詳細設定このオプションを使用して、複数のテキストタイプを選択するか、カスタムのテキストタイプを指定します。このオプションでは、パターンファイルをPTNまたはFBT形式で読み込むこともできます。 パターンの読み込みは、変更...をクリックします。表示されたダイアログボックスで、使用パターンを選択し、ファイルへのパスを指定します。
パターン
 重要!パターントレーニングはアジア言語ではサポートされていません。
重要!パターントレーニングはアジア言語ではサポートされていません。- マーキングタイプマーキングタイプを選択します。 選択の簡略化で、ドロップダウンリストからサンプルを選択します。スキャン中にマーキングが消えると、マーキングタイプはモノスペース(灰色のボックス)になります。スキャン中にマーキングが消えず、文字スペースのセルに分割されている場合は、合計セル数を入力する必要があります。プログラムが自動でそのようなマーキングを持つフィールドを検出すると、セルの数も自動で決定されます。
 注: 一部のマーキングタイプ(グレーボックス、シンプルと下線付き)では、行末で分割された単語が自動的に再び結合されます。選択されたマーキングタイプがシンプルまたは下線付きの場合、単語の分割にハイフンが使用されていた場合のみ、単語が結合されます。グレーボックスのマーキングタイプが使用されている場合、ハイフンが使用されていなくても、分割された単語が検出されて結合されます。辞書で検出された場合、その単語は再び結合されます。
注: 一部のマーキングタイプ(グレーボックス、シンプルと下線付き)では、行末で分割された単語が自動的に再び結合されます。選択されたマーキングタイプがシンプルまたは下線付きの場合、単語の分割にハイフンが使用されていた場合のみ、単語が結合されます。グレーボックスのマーキングタイプが使用されている場合、ハイフンが使用されていなくても、分割された単語が検出されて結合されます。辞書で検出された場合、その単語は再び結合されます。 - 大文字フィールド内の文字の大文字と小文字を選択します。小文字と大文字の両方が可能な場合は、自動オプションが有効になっていることが必要です。
- 向きテキストの向きを指定します。
- CJK テキストの向き – 中国語、日本語、または韓国語の場合、OCRに使用する読み取り方向を選択します。あり得るオプションは、自動、横書き、または縦書きです。デフォルトは自動に設定されています。CJKテキストを含んでいないフィールドについてはこのオプションをおすすめします。
- 1 行 – 常に1行で構成されるフィールドにはこのオプションを選択してください。このオプションを使用すると、認識の悪い文字や高さの異なる文字のために、フィールド内のテキストが複数行のテキストとして解釈されることがなくなります。注:複数行のフィールドでは、このオプションを無効にします。
- 値が常に1つの単語で構成されるフィールドの場合、1 単語オプションを有効にします。このオプションは、フィールド内の単語数に関係なくフィールド全体に正規表現を適用する場合に、有効化できます。注:このオプションを有効にした場合、1 単語カスタム辞書にスペース文字を含む数式を置くことはお勧めしません。
画像の事前処理設定の設定方法:
- 反転認識時に画像の色と明るさを反転させます(この反転は一時的なもので、影響するのは認識のみです。 元の画像の色は出力ファイルに保持されます)。
- 自動検出テキストの色と背景色を自動的に検出し、必要に応じて反転します。暗い背景に明るいテキスト、明るい背景に暗いテキストの両方を含むように推奨する文書設定です。
- 反転画像を完全に反転させます。
- 反転しない元の色のままにします(既定で有効)。
- テクスチャを削除テクスチャを削除
- 斑点削除このオプションを有効にすると、画像からゴミを除去します。
- 指定したサイズのゴミのみを消去指定した大きさのゴミだけ除去する場合は、このオプションを有効にしてください。ゴミの大きさを指定します。このオプションが無効で、斑点削除オプションが有効になっていると、ゴミのサイズが自動で選択されます。
4/12/2024 6:16:25 PM