Dokument-Workflow
Die folgenden Verarbeitungsschritte werden durchgeführt, beginnend mit der Bildeinreichung zu ABBYY FineReader Server 14 und endend mit dem Export:
- Scannen/Import
- Verarbeitung
- Dokumententrennung
- Überprüfung (optional)
- Indexierung (optional)
- Exportieren
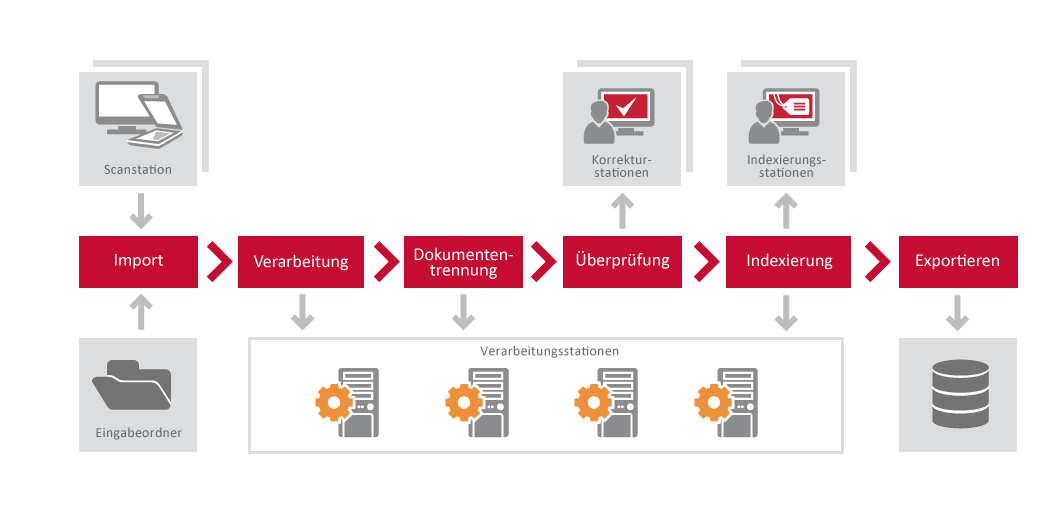
Scannen/Import
Zu diesem Zeitpunkt werden Bilder entweder auf der Scanstation gescannt oder von ABBYY FineReader Server aus einem Hot Folder oder einer Mailbox oder mithilfe des Dienst für die Dokumentenkonvertierung in ABBYY FineReader Server 14 importiert.  Hinweis. Die Bilddateien werden standardmäßig nach Name sortiert und an den Server Manager in lexikografischer Reihenfolge gesendet (d. h., file10.jpg kommt vor file2.jpg). Dies kann in den Servereinstellungen geändert werden. Weitere Informationen finden Sie unter Dialogfeld: FineReader Servereigenschaften.
Hinweis. Die Bilddateien werden standardmäßig nach Name sortiert und an den Server Manager in lexikografischer Reihenfolge gesendet (d. h., file10.jpg kommt vor file2.jpg). Dies kann in den Servereinstellungen geändert werden. Weitere Informationen finden Sie unter Dialogfeld: FineReader Servereigenschaften.
Nachdem die Bilddateien von der Scanstation, dem Eingabeordner oder Postfach an den Server Manager gesendet wurden, erstellt der Server Manager Jobs für sie und stellt diese zur Verarbeitung in die Warteschlange. Wenn mehrere Workflows eingerichtet wurden, verarbeitet der ABBYY FineReader Server Jobs aus allen Workflows gleichzeitig in einer Warteschlange. Die Jobs werden in der Warteschlange entsprechend Ihrer Erstellungszeit und ihrer Priorität angeordnet.
Hinweis. Der Server Manager speichert alle Bilddateien im Bild-Unterordner des temporären ABBYY FineReader Server 14-Ordners. Den Pfad zum temporären Ordner des Server Managers können Sie im Dialogfeld Eigenschaften von FineReader Server der Remote-Verwaltungskonsole anzeigen und ändern. Die Bilddateien werden während des gesamten Konvertierungsprozesses in diesem Ordner gespeichert. Die Verarbeitungsstationen, Korrekturstationen und Indexierungsstationen erhalten für die Verarbeitung lediglich Kopien dieser Bilder. Damit wird sichergestellt, dass keine Dateien verloren gehen, falls bei der Erkennung, Überprüfung oder Indexierung ein Fehler auftritt.
Tipps für das Scannen
Die Konvertierungsqualität hängt von der Qualität des Originaldokuments und den Scanparametern ab. Eine schlechte Bildqualität kann sich nachteilig auf die Qualität der Konvertierung auswirken. Wählen Sie die für Ihr Dokument geeigneten Scanparameter aus.
Wir empfehlen ein Scannen von Dokumenten mit 300 dpi.
 Wichtig! Die vertikale und die horizontale Auflösung müssen gleich sein.
Wichtig! Die vertikale und die horizontale Auflösung müssen gleich sein.
Durch die Einstellung einer zu hohen Auflösung (über 600 dpi) verlängert sich die Erkennungszeit. Eine Erhöhung der Auflösung führt nicht zwangsläufig zu einem besseren Erkennungsergebnis. FineReader Server unterstützt Auflösungen bis zu 3200 dpi. Höhere Auflösungen werden automatisch reduziert.
Die Einstellung einer extrem niedrigen Auflösung (weniger als 150 dpi) kann sich negativ auf die Erkennungsqualität auswirken.
Empfehlungen für die Auswahl der Auflösung hängen von der Schriftgröße ab:
- 300 dpi – für typische Texte (gedruckt mit einer Schriftgröße von 10 pt oder größer)
- 400–600 dpi – für Texte mit kleinerer Schrift (9 pt oder kleiner) und Bilder mit Strichcodes.
OCR
Der erste Job in der Warteschlange wird an die erste freie Verarbeitungsstation zur Erkennung übermittelt. Wenn das System mehrere Verarbeitungsstationen umfasst, verteilt der Server Manager die Jobs aus der Warteschlange gleichmäßig auf diese Verarbeitungsstationen. Siehe Registrieren einer neuen Verarbeitungsstation.
Auf einer Verarbeitungsstation können mehrere OCR-Prozesse ausgeführt werden (die Anzahl können Sie in der Remote-Verwaltungskonsole anpassen). Für eine optimale Leistung sollte die Anzahl der Prozesse pro Station n+1 lauten, wobei n die Anzahl der CPU-Kerne der Station ist. Normalerweise wird jedem OCR-Prozess immer genau eine Datei zugeordnet. Wenn z. B. eine Verarbeitungsstation zwei OCR-Prozesse ausführt, führt sie parallel den Erkennungsprozess für zwei Dateien durch (die zu einem oder zu unterschiedlichen Jobs gehören können). Wenn die Datei jedoch sehr viele Seiten umfasst (z. B. mehrere Dutzend), wird die große Datei in mehrere Teile aufgeteilt und auf unterschiedliche OCR-Prozesse verteilt, damit der Job schneller abgeschlossen werden kann.
Nach Abschluss der Dateiverarbeitung übergibt die Verarbeitungsstation die erkannte Datei wieder an den Server Manager und erhält den nächsten Job aus der Warteschlange.
Dokumententrennung
Nach der Erkennung werden die Seiten in der Jobwarteschlange entsprechend der Trennungsregel zu neuen Dokumenten zusammengefasst. Die Dokumententrennung wird innerhalb eines Jobs durchgeführt. Je nachdem, welche Quelle im Importarbeitsgang ausgewählt wurde, stehen verschiedene Methoden der Dokumententrennung zur Verfügung. Neben den integrierten Methoden zur Aufteilung von Dokumenten (nach Strichcodes, Leerseiten usw.) kann über die Verwendung eines Skripts eine Trennung durchgeführt werden. Siehe Konfiguration der Dokumententrennung.
Überprüfung
Wenn in den Workflow-Einstellungen die Überprüfung aktiviert wurde, werden Dokumente, für die eine Überprüfung erforderlich ist, nach der Zusammenstellung in die Warteschlange für die Überprüfung eingefügt.. Sofern Korrekturstationen angeschlossen wurden, leitet der Server Manager die Dokumente in der Warteschlange an diese Stationen weiter. Wenn zurzeit keine Korrekturstationen angeschlossen sind oder die an den Stationen angemeldeten Benutzer nicht über die entsprechenden Berechtigungen für die Überprüfung von Dokumenten aus diesem Workflow verfügen, verbleiben die Dokumente in der Warteschlange und erhalten den Status "Zur Überprüfung in Warteschlange gestellt". Diese werden erst nach einer Überprüfung zur weiteren Verarbeitung übermittelt. Siehe Konfiguration der Überprüfung.
Indexierung
Wurden Dokumententypen und attribute in den Workflow-Einstellungen definiert, werden die in diesem Workflow zusammengestellten Dokumente zur Indexierung in die Warteschlange gestellt. Die Indexierung kann mithilfe eines Skripts automatisch und/oder manuell in einer Indexierungsstation durchgeführt werden. Ist ein Skript definiert, wird die Indexierung zuerst entsprechend des Skripts durchgeführt. Dann werden die Dokumente, die eine manuelle Indexierung oder Indexüberprüfung benötigen, in die Warteschlange der Indexierungsstationen gestellt. Sofern Indexierungsstationen angeschlossen sind, leitet der Server Manager die Dokumente in der Warteschlange an diese Stationen weiter. Wenn zurzeit keine Indexierungsstationen angeschlossen sind oder die an den Stationen angemeldeten Benutzer nicht über die entsprechenden Berechtigungen für die Indexierung von Dokumenten aus diesem Workflow verfügen, verbleiben die Seiten in der Warteschlange und erhalten den Status „Zur Indexierung in Warteschlange gestellt“. Siehe Konfiguration der Dokumentenindexierung.
Exportieren
Nach Abschluss von Erkennung, Korrektur und Indexierung werden die Ausgabedokumente zurück an den Server Manager übergeben und in die Warteschlange für die Veröffentlichung eingefügt. Der Server-Manager liefert die Ausgabedokumente an das in den Auftragseinstellungen angegebene Ziel oder bietet Ihnen die Möglichkeit, sie an einem Speicherort Ihrer Wahl zu speichern, wenn Sie den Dienst für die Dokumentenkonvertierung in ABBYY FineReader Server 14 verwenden. Nachdem die Ausgabedateien im Ausgabeordner veröffentlicht wurden, wird die Bildkopie aus dem temporären Ordner des Server Managers gelöscht.
Wurde das den Export verarbeitende Skript für erfolgreich veröffentlichte Jobs definiert, wird dieses ausgeführt, sobald die Ausgabedokumente und XML-Ergebnisse im Ausgabeordner veröffentlicht werden. Das den Export verarbeitende Skript kann dafür verwendet werden, die Ausgabedokumente je nach Dokumententyp, Dokumentattribute, Erkennungsstatistiken usw. an ein entsprechendes Ziel zu senden.
Ein Skript für fehlgeschlagene Jobs kann definiert werden, um so Bilder zu verarbeiten, deren Verarbeitung nicht geklappt hat und die daraufhin in den Ausnahmenordner abgelegt wurden.
26.03.2024 13:49:48