- English (English)
- Bulgarian (Български)
- Chinese Simplified (简体中文)
- Chinese Traditional (繁體中文)
- Czech (Čeština)
- Danish (Dansk)
- Dutch (Nederlands)
- French (Français)
- Greek (Ελληνικά)
- Hungarian (Magyar)
- Italian (Italiano)
- Japanese (日本語)
- Korean (한국어)
- Polish (Polski)
- Portuguese (Brazilian) (Português (Brasil))
- Slovak (Slovenský)
- Spanish (Español)
- Swedish (Svenska)
- Turkish (Türkçe)
- Ukrainian (Українська)
- Vietnamese (Tiếng Việt)
Vor dem Erkennungsvorgang zu berücksichtigende Dokumenteigenschaften
Die Qualität der Bilder hat einen wesentlichen Einfluss auf die OCR-Qualität. In diesem Abschnitt wird erläutert, welche Faktoren vor der Erkennung von Bildern berücksichtigt werden sollten.
ABBYY FineReader erkennt sowohl ein- als auch mehrsprachige Dokumente (z. B. in zwei oder mehr Sprachen verfasst). Bei mehrsprachigen Dokumenten müssen Sie mehrere OCR-Sprachen auswählen.
Für die Auswahl der OCR-Sprachen klicken Sie auf Optionen > Sprachen und wählen eine der folgenden Optionen:
- OCR-Sprachen automatisch aus der folgenden Liste auswählen
ABBYY FineReader wählt automatisch die entsprechenden Sprachen aus der benutzerdefinierten Sprachenliste aus. So bearbeiten Sie die Sprachenliste: - Vergewissern Sie sich, dass die Option OCR-Sprachen automatisch aus der folgenden Liste auswählen aktiviert ist.
- Klicken Sie auf die Schaltfläche Auswählen....
- Wählen Sie im Dialogfeld Sprachen die gewünschten Sprachen und klicken Sie auf OK.
- Klicken Sie im Dialogfeld Optionen auf OK.
- OCR-Sprachen manuell festlegen
Wählen Sie diese Option, wenn die benötigte Sprache in der Liste nicht aufgeführt ist.
Legen Sie unten im Dialogfeld eine oder mehrere Sprache(n) fest. Wenn Sie oft eine bestimmte Sprachkombination verwenden, können Sie eine neue Gruppe für diese Sprachen erstellen.
Befindet sich eine Sprache nicht in der Liste:
- Wird diese von ABBYY FineReader nicht unterstützt oder
 Eine vollständige Liste der unterstützten Sprachen finden Sie unter Unterstützte OCR-Sprachen.
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Unterstützte OCR-Sprachen. - Wird von Ihrer Version des Produkts nicht unterstützt. Eine vollständige Liste der Sprachen, die in Ihrer Version des Produkts verfügbar sind, finden Sie im Dialogfeld Lizenzen (klicken Sie auf Hilfe > Über... > Lizenzinformationen, um dieses Dialogfeld zu öffnen).
Neben den integrierten Sprachen und Sprachgruppen können Sie auch Ihre eigenen Sprachen und Gruppen erstellen. Siehe auch: Wenn das Programm bestimmte Zeichen nicht erkannt hat.
Dokumente können auf verschiedenen Geräten, wie beispielsweise Schreibmaschinen und Faxgeräten, erstellt worden sein. Die OCR-Qualität kann in Abhängigkeit davon, wie das Dokument ausgedruckt wurde, variieren. Sie können die OCR-Qualität verbessern, indem den korrekten Drucktyp im Dialogfeld Optionen auswählen.
Bei den meisten Dokumenten erkennt das Programm den Drucktyp automatisch. Für eine automatische Erkennung des Drucktyps muss die Option Autom. in der Optionsgruppe Dokumenttyp im Dialogfeld Optionen aktiviert sein (klicken Sie auf Werkzeuge > Optionen... > OCR, um auf diese Optionen zuzugreifen). Sie können ein Dokument im Vollfarb- oder im Schwarzweiß-Modus verarbeiten.
Bei Bedarf kann der Drucktyp auch manuell ausgewählt werden.
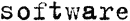 |
Ein Beispiel für einen Schreibmaschinentext. Alle Zeichen haben dieselbe Breite (vergleichen Sie z. B. "w" und "t"). Wählen Sie bei diesen Texten Schreibmaschine. |
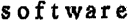 |
Ein Beispiel für Text aus einem Faxgerät. Wie Sie am Beispiel erkennen können, sind einige der Buchstaben nicht klar zu erkennen. Außerdem gibt es einige Störungen und Verzerrungen. Wählen Sie bei diesen Texten Fax. |
Nach der Erkennung von Schreibmaschinen- oder Faxtexten muss vor der Verarbeitung normal gedruckter Dokumente unbedingt Autom. ausgewählt werden.
Dokumente in schlechter Qualität mit “Rauschen” (d. h. verstreuten schwarzen Punkten oder Flecken), unscharfen bzw. ungleichmäßigen Buchstaben oder schiefen Zeilen und verschobenen Tabellenbegrenzungen benötigen u. U. spezifische Scaneinstellungen.
| Fax | Zeitung |
 |
 |
Dokumente in schlechter Qualität werden am besten in Graustufen gescannt. Dabei wählt das Programm automatisch den optimalen Wert für die Helligkeit aus.
Der Graustufen-Scanmodus bewahrt mehr Informationen über die Buchstaben im gescannten Text, wodurch beim Erkennen von Dokumenten mittlerer bis schlechter Qualität bessere OCR-Ergebnisse erhalten werden. Mit den im Bildeditor verfügbaren Werkzeugen können Sie einige der Mängel auch manuell korrigieren. Siehe auch: Wenn Ihr Dokumentbild Fehler enthält und bei niedriger OCR-Genauigkeit.
Müssen die Farben in einem Vollfarbdokument nicht erhalten bleiben, können Sie das Dokument im Schwarzweiß-Modus verarbeiten. Dadurch wird die Größe des resultierenden OCR-Projekts erheblich reduziert und der OCR-Vorgang beschleunigt. Werden jedoch Bilder mit niedrigem Kontrast im Schwarzweiß-Modus verarbeitet, ist die resultierende OCR-Qualität möglicherweise schlecht. Darüber hinaus empfehlen wir die Schwarzweiß-Verarbeitung nicht für Fotos, Zeitschriftenseiten und Texte auf Chinesisch, Japanisch und Koreanisch.
Tipp. Sie können die Geschwindgkeit der Erkennung von Farb- und Schwarzweiß-Dokumenten auch beschleunigen, indem Sie Schnelle Erkennung auf der Registerkarte OCR des Dialogfelds Optionen aktivieren. Weitere Informationen über die Erkennungsmodi finden Sie unter OCR-Optionen.
Weitere Empfehlungen für die Auswahl des richtigen Farbmodus finden Sie unter Tipps für das Scannen.
 Nachdem ein Dokument zu Schwarzweiß konvertiert wurde, können die Farben nicht wiederhergestellt werden. Um ein Farbdokument zu erhalten, öffnen Sie eine Datei mit Farbbildern oder scannen das Papierdokument im Farbmodus.
Nachdem ein Dokument zu Schwarzweiß konvertiert wurde, können die Farben nicht wiederhergestellt werden. Um ein Farbdokument zu erhalten, öffnen Sie eine Datei mit Farbbildern oder scannen das Papierdokument im Farbmodus.
3/4/2022 7:13:05 AM