- English (English)
- Bulgarian (Български)
- Chinese Simplified (简体中文)
- Chinese Traditional (繁體中文)
- Czech (Čeština)
- Danish (Dansk)
- Dutch (Nederlands)
- French (Français)
- German (Deutsch)
- Greek (Ελληνικά)
- Hungarian (Magyar)
- Italian (Italiano)
- Japanese (日本語)
- Korean (한국어)
- Polish (Polski)
- Portuguese (Brazilian) (Português (Brasil))
- Slovak (Slovenský)
- Swedish (Svenska)
- Turkish (Türkçe)
- Ukrainian (Українська)
- Vietnamese (Tiếng Việt)
El reconocimiento en segundo plano
El Editor PDF le permite buscar y copiar texto e imágenes de los documentos PDF sin capa de texto, como documentos digitalizados y documentos creados a partir de archivos de imagen. Esto es posible gracias a un proceso OCR que se ejecuta en segundo plano.
El reconocimiento en segundo plano está habilitado por defecto, y se inicia automáticamente cuando abre un documento PDF.
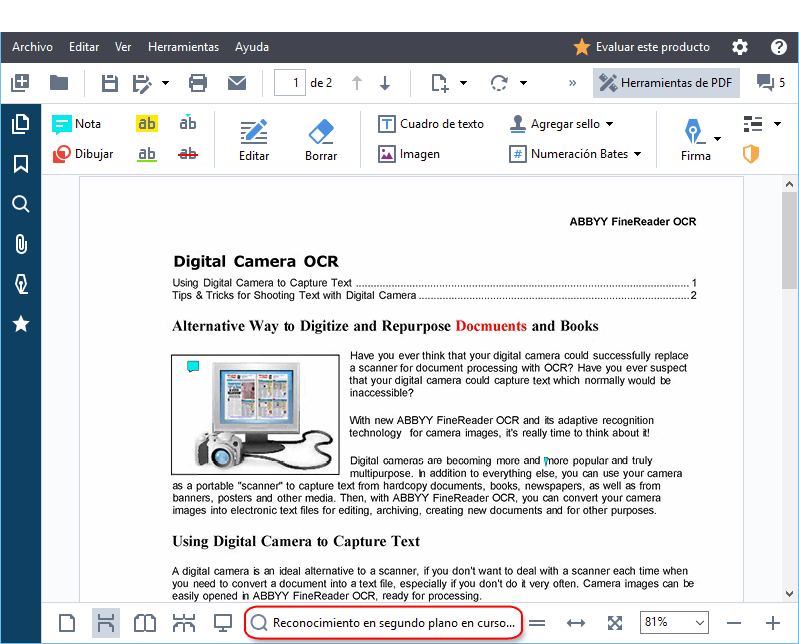
El proceso de reconocimiento en segundo plano no cambia el contenido del archivo PDF. En vez de eso, agrega una capa de texto temporal que no estará disponible cuando abra el documento en otras aplicaciones.
 Si desea que el documento permita la búsqueda en otras aplicaciones, tendrá que guardar la capa de texto creada por el proceso de reconocimiento en segundo plano. Para ello, haga clic en Archivo > Reconocer documento > Reconocer documento... Consulte también: Reconocer texto.
Si desea que el documento permita la búsqueda en otras aplicaciones, tendrá que guardar la capa de texto creada por el proceso de reconocimiento en segundo plano. Para ello, haga clic en Archivo > Reconocer documento > Reconocer documento... Consulte también: Reconocer texto.
 ¡Importante! Si las funciones de búsqueda yde copia no funcionan correctamente, compruebe que se han seleccionado los idiomas de OCR correctos para el documento. Consulte también: Características del documento que se deben tener en cuenta antes del OCR.
¡Importante! Si las funciones de búsqueda yde copia no funcionan correctamente, compruebe que se han seleccionado los idiomas de OCR correctos para el documento. Consulte también: Características del documento que se deben tener en cuenta antes del OCR.
 Para deshabilitar el reconocimiento en segundo plano, deshabilite la Habilitar reconocimiento en segundo plano en editor de PDF opción en el Opciones cuadro de diálogo.
Para deshabilitar el reconocimiento en segundo plano, deshabilite la Habilitar reconocimiento en segundo plano en editor de PDF opción en el Opciones cuadro de diálogo.
El proceso de reconocimiento en segundo plano no se puede ejecutar en equipos con procesador de un solo núcleo.
04.03.2022 7:13:07