How to calculate the number of Processing Stations
To make the most of computing resources, each Station runs multiple processing threads at the same time; the more CPU cores there are available, the more parallel threads are processed. Since the number of CPU cores varies from computer to computer, it makes sense to count the total number of processing CPU cores in the FlexiCapture System.
If there are no bottlenecks in the System, each new processing core makes an equal contribution to the performance of the entire System. Hence, you need to estimate the contribution of one core and then estimate how many cores you need to achieve target performance.
The number of pages a processing core is able to process during a period of time depends greatly on processing workflow (e.g. number of stages), processing settings (image enhancement operation, recognition mode, export settings), custom stage implementation (custom engines and script rules, accessing external resources), and on hardware. When you have no idea about any of these details, but already need some estimation, you can use the following graph as a baseline. Most likely, however, you will get other results in your project.
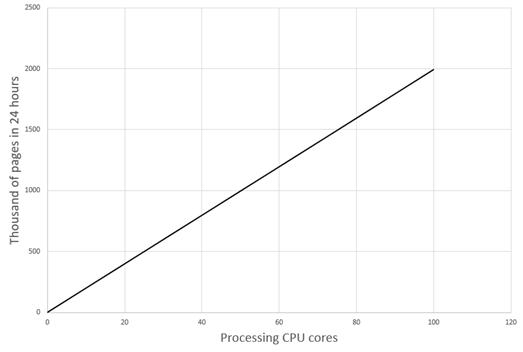
|
The dependence of performance on the number of processing cores Configuration The “SingleEntryPoint” Demo project: unattended processing, export to PDF files. For black&white pages: 10 core processing stations, 2.4GHz, 16GB RAM, SSD, 1 Gb/s NIC. |
To estimate the required number of processing cores, you may do as follows:
- Configure your project workflow, take the Processing Station that is the closest in terms of hardware parameters to what is going to be used in production, and create a typical batch of images.
- We are going to measure how long it takes to process one batch for one core.
It is not enough to process one batch only once, because FlexiCapture may distribute the processing between all available cores, and it will take less time to process one batch during tests, while during real production other cores will be occupied, processing other batches.
For a reliable estimate, we recommend creating several copies of your typical batch – at least the same number as the number of cores, but it is better to multiply it by N (which is at least 3) to minimize the error of measurement, and place them all into processing simultaneously. The time required to process one batch per core is then the total processing time divided by N. This estimation takes into account the possible competition between processing cores over shared resources of the Processing Station.
Example. We have an 8-core Processing Station with Hyper-Treading enabled, which gives us 16 logical cores and executive processes at this Station. We need to create at least 16 copies of a typical batch, but we had better create 16 x 3 = 48 copies to minimize the measurement error. We put all batches in the FlexiCapture hotfolder, start the timer at the first import task created and stop it after the last result has been exported to the backend – it will show 15 minutes. This time each core has to process 3 batches, hence the time to process 1 batch is about 5 minutes. Our batch has 69 pages, and we can say it takes 4.35 seconds to process 1 page. - Once we know the desired performance in pages per hour or day, we can come up with an estimation of the desired number of cores.
Assume you need to process P pages in T time. We already know from the above that 1 core needs t time to process 1 page. Hence, you need N = (P x t ) / T cores.
Example. A customer needs to process 200,000 pages in 8 hours, which is 28,800 seconds. As we know from the above, 1 core takes 4.35 seconds to process 1 page. Hence, we need (200,000 x 4.35) / 28,800 = 31 cores. Thus, 2 Processing Stations with 8 cores and Hyper-Threading enabled (32 logical cores in total) will be sufficient for automatic processing.
There are 2 limiting factors as regards the number of processing cores in the System:
- The total load on the infrastructure that may result in bottlenecks:
- - on the FlexiCapture server hardware;
- - on the network; or
- - on external shared resources (like databases, external services, etc.) that are requested from custom processing scripts.
A bottleneck will result in performance saturation – adding a new processing core will have a negative or simply no effect on the total performance. This document describes how to design the System to avoid bottlenecks (see above) and how to monitor the hardware and infrastructure for bottlenecks.
Still, even if there are no clearly detected bottlenecks, the competition between processing cores over shared resources grows when new cores are added to the System. If you are going to utilize more than 50% of the network’s or FileStorage’s read/write capacity (according to calculations in this document), then add 20% to the processing time of each page in the above examples – that will actually result in a need for 20% more processing cores in the System.
Use caching for processing cores to access external resources faster – e.g., instead of connecting directly to the database, connect it to the FlexiCapture Data Set and then request the Data Set from the scripts.
- The number of processing cores that can be served by the Processing Server. This number depends on the average time a core needs to perform a task. This time depends greatly on batch size (in pages) and implemented customization. Usually, if you have around 10 pages in a batch, the Processing Server is able to serve 120 processing cores. However, if you create a large number of custom stages with very fast scripts, or are going to process one page per batch, you will significantly decrease the average task time, which may result in a slight decrease of the maximum number of processing cores.
 Note: To detect this problem, you need to monitor the Free Processing Cores counter on the Processing Server. If you see that, despite this, you have a queue of documents to process, the number of occupied cores has reached saturation at some point and almost never goes higher, you have achieved the described effect. To cure this:
Note: To detect this problem, you need to monitor the Free Processing Cores counter on the Processing Server. If you see that, despite this, you have a queue of documents to process, the number of occupied cores has reached saturation at some point and almost never goes higher, you have achieved the described effect. To cure this:
- process the entire batch without splitting it to little tasks, where possible (see the Stage Properties in the Workflow settings dialog),
- process pages by bigger portions: increase the average number of pages per batch, merge several custom stages into one, or bring the customization to a standard stage, e.g. by adding it to a routing event in that stage’s script.
4/12/2024 6:16:02 PM