Searching for strings of digits
An element of type Character String is used to search for digit strings. If the image quality is very good, then even a regular expression can be specified as an alphabet. But if the quality of images in the batch differs, we must specify the list of characters that can be recognized in the corresponding field. If the quality of images or print is non-satisfactory, digits can be mistakenly recognized as other characters. For example - "8" can be recognized as "B", "7" - as "?", "5" - as "S", "4" - as "H" or the letter combination "LI", etc. This can happen if the digits are "glued", which is common if documents are filled in by using a typewriter.
The degree of correspondence between the results of recognition and the actual characters depends on the image quality. If there is a tendency to misinterpret characters on all or most of the processed images, then you should add these recognition variants to the alphabet in the Edit Alphabet window of the corresponding element Character String. By specifying these characters, you tell the program not to penalize the hypothesis if these characters are encountered in the search area.
 Note.Certainly, there is no need to specifyallthe possible recognition variants. If the quality of the images is bad, it may be an extremely time-consuming task to find all such variants. If, because of low image quality, the results of the recognition are unpredictable, then you should run the search by using some other element properties, such as string length, length of spaces in the string, etc.
Note.Certainly, there is no need to specifyallthe possible recognition variants. If the quality of the images is bad, it may be an extremely time-consuming task to find all such variants. If, because of low image quality, the results of the recognition are unpredictable, then you should run the search by using some other element properties, such as string length, length of spaces in the string, etc.
Specify the characters whose outlines are similar to those of digits. The chances of incorrect recognition for such characters are higher than for the rest. If required, you can specify other characters as well, if they are commonly mistaken for digits.
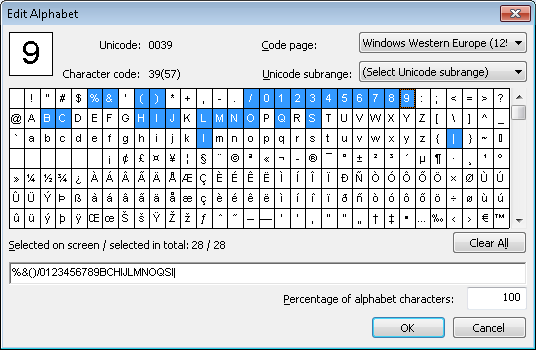
Let's consider the project 1.fsp (folder Digital strings\Project1).
The project has 3 pages.
- Page 1 – the digit 4 is recognized as the combination of letters "LI";
- Page 2 – the substring 13 is recognized as the letter "å";
- Page 3 – the digit 0 is recognized as "a", 2 and 5 are recognized as "S", 6 and 8 – as "B".
To detect the digit string, we created an element of type Character String, named it DigitalString and specified only digits as its alphabet. We set the maximum percentage of non-digit characters at 20.
After running the FlexiLayout matching procedure on all the pages, the digit field on page 3 wasn't fully detected. The quality value of the hypothesis is about 0.98. On pages 1 and 2, the string has been detected. But since it contains non-alphabetic characters, the corresponding hypotheses were penalized and their quality made 0.978 and 0.982 respectively.
Now let's see the results of the FlexiLayout matching if we add to the alphabet the characters that were mistakenly recognized instead of digits: L, I, e, a, B, S.
The result of the FlexiLayout matching can be seen in the project 2.fsp (folder %public%\ABBYY\FlexiCapture\12.0\Samples\FLS\Tips and Tricks\Digital strings\Project2).
The other settings in the projects are identical.
As you can see, the string on page 3 has been fully detected, and the quality of all the generated hypotheses is 1.
12.04.2024 18:16:02